
Machen Sie Ihre Unternehmensdokumente KI‑bereit — zuverlässig, vor Ort und semantisch.
Es ist ein häufiger Fall, dass Organisationen ihre Dokumentation in den Formaten PDF, DOCX, XLSX und ePub aufbewahren. Während LLMs (Large Language Models) gut mit HTML oder Klartext arbeiten, müssen diese nativen Dokumentenformate konvertiert werden, bevor sie effektiv in LLM + RAG‑Pipelines eingesetzt werden können, in denen wir mit einem Dokument oder einer Dokumentensammlung chatten wollen.
LLM (Large Language Model) — ein vortrainiertes KI‑Modell, das Text generiert und Antworten basierend auf großen Textkorpora liefert.
RAG (Retrieval‑Augmented Generation) — ein Ansatz, der ein LLM mit einer externen Wissensbasis (z. B. Unternehmensdokumenten) kombiniert, sodass das Modell Inhalte abrufen und darüber reasoning kann.
Das folgende Sequenzdiagramm veranschaulicht die typischen Schritte, die bei der Erzeugung einer Antwort auf eine Frage ablaufen:
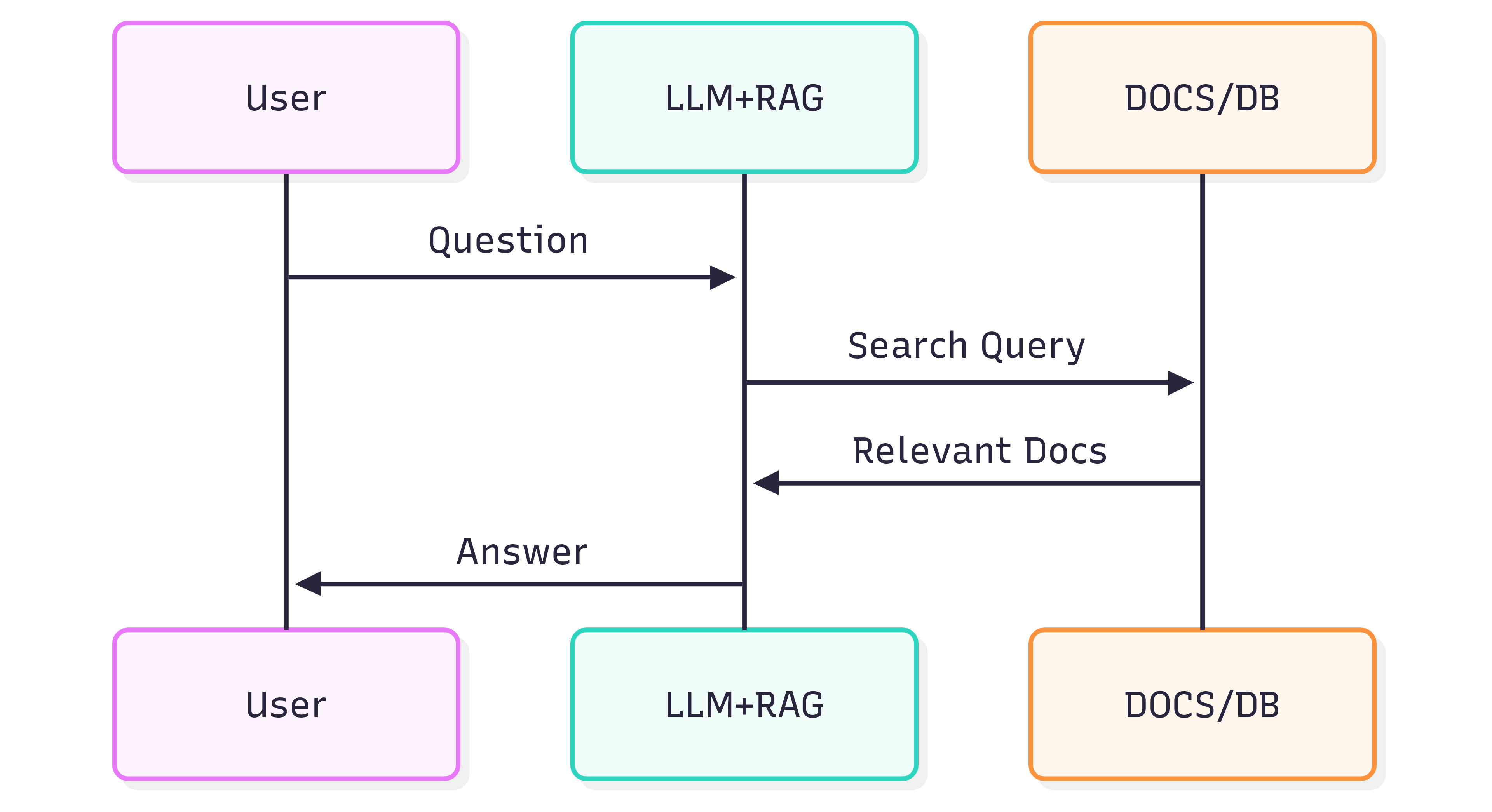
Die Qualität der Antworten, die Sie von einem System (LLM + RAG) erhalten, hängt sowohl vom System selbst als auch davon ab, wie gut die Quelldokumente ihre Struktur und Bedeutung bewahren, wenn sie in die Retrieval‑Pipeline eingespeist werden.
Das Problem
Dokumentformatierung ist nicht nur visuell — sie trägt Semantik. Überschriften, Listen, Tabellen, fett/kursiv Hervorhebungen, Bildunterschriften und Inline‑Bilder vermitteln Bedeutungen, die einem LLM helfen, den Kontext zu verstehen. Naives Konvertieren von Dokumenten (z. B. mittels OCR, das jede Seite als flaches Bild behandelt) verliert häufig diese Semantik. Infolgedessen können RAG‑Abrufe und nachgelagerte LLM‑Antworten ungenau oder verrauscht werden.
OCR kann bei gescannten Dokumenten helfen, entfernt jedoch häufig die Struktur (Listen, die sich über Seiten erstrecken, Tabellenränder, die falsch interpretiert werden, verlorene Anmerkungen). Außerdem verursacht es Kosten und Infrastruktur‑Overhead bei der Verarbeitung großer Archive.
Die Lösung
Ein alternativer Ansatz besteht darin, Dokumente mit strukturellem Bewusstsein zu parsen und diese Struktur in ein semantisches, LLM‑freundliches Format zu exportieren — Markdown. Markdown ist leichtgewichtig, weit verbreitet und bewahrt Überschriften, Listen, Tabellen, Code‑Blöcke, Hervorhebungen, Bildunterschriften und Bildreferenzen — genau die Features, die die Retrieval‑Qualität verbessern.
GroupDocs.Markdown for .NET konvertiert gängige Dokumentformate (PDF, DOCX, XLSX, ePub und mehr) in sauberes, semantisches Markdown, das für die Aufnahme in RAG‑Systeme geeignet ist. Es ist eine On‑Premise‑.NET‑Bibliothek, sodass die gesamte Verarbeitung in Ihrer Umgebung stattfindet — keine externen Dienste, kein Datenverlust und keine Abhängigkeit von entfernten GPUs.
Erste Schritte
GroupDocs.Markdown for .NET ist als NuGet‑Paket sowie als MSI‑ und ZIP‑Download verfügbar.
Installieren Sie das NuGet‑Paket mit der .NET‑CLI:
dotnet add package GroupDocs.Markdown
Oder laden Sie Installer und Assemblies von der offiziellen Download‑Seite herunter: https://releases.groupdocs.com/markdown/net/
Beispiel‑Verwendung (zu Program.cs hinzufügen):
// Import the namespace
using GroupDocs.Markdown;
// Set the license (optional for evaluation)
License.Set("GroupDocs.Markdown.lic");
// Instantiate the converter for a source document
var converter = new MarkdownConverter("rich-text-formatting.docx");
// Convert and save output to file
converter.Convert("rich-text-formatting.md");
Die konvertierte Datei rich-text-formatting.md wird im selben Ordner wie Ihre Anwendung gespeichert.
Der folgende Screenshot zeigt die Eingabe‑DOCX‑Datei und das resultierende Markdown.
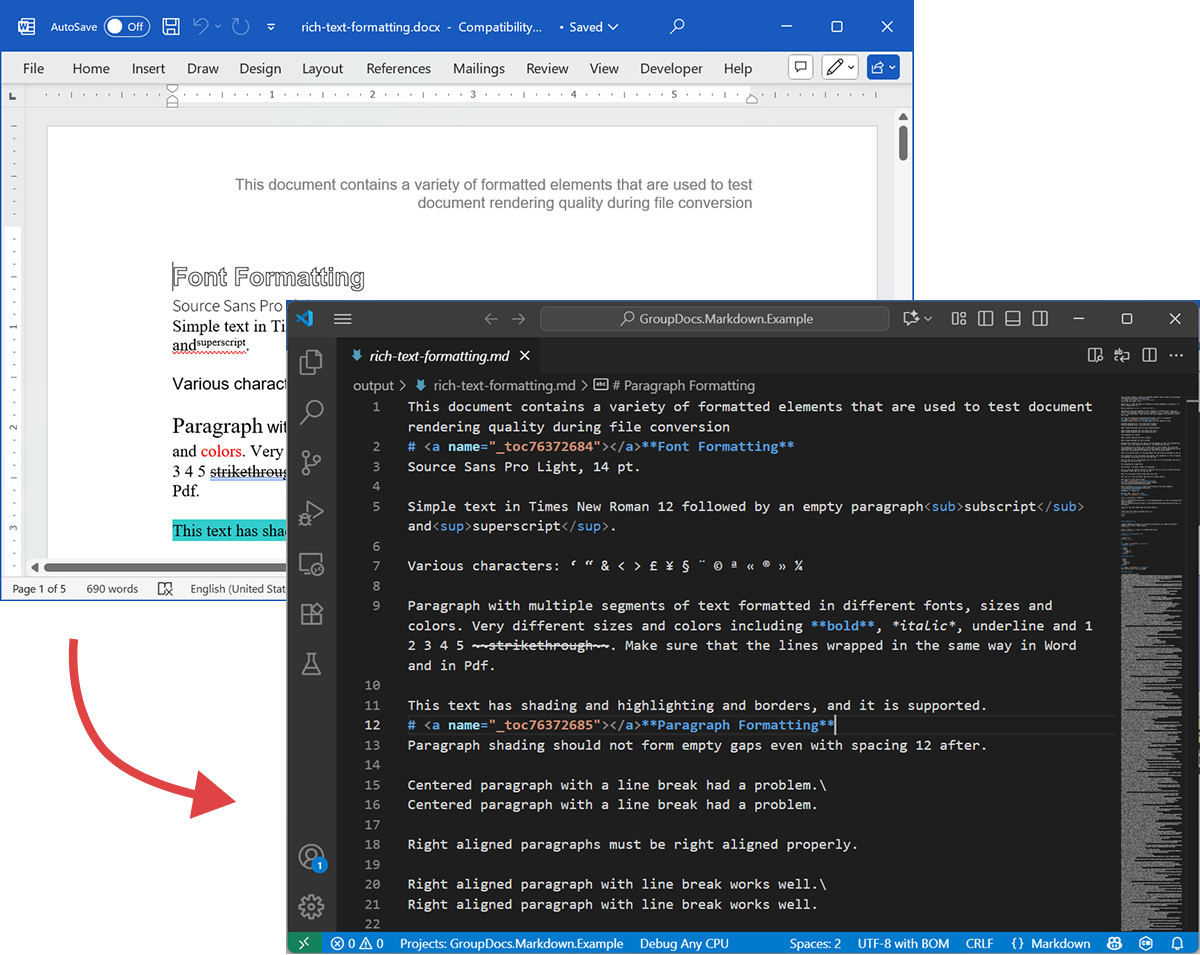
Wenn Sie ohne Lizenz arbeiten, verarbeitet der Evaluierungsmodus nur eine begrenzte Anzahl von Seiten (z. B. die ersten drei Seiten). Um das vollständige Produkt zu testen, fordern Sie eine temporäre Lizenz an.
Um eine temporäre Lizenz anzufordern, öffnen Sie den Purchase Wizard, geben Sie Ihre Kontaktdaten ein und klicken Sie im Schritt Contact Details auf Get a temporary license. Die temporäre Lizenz wird Ihnen per E‑Mail zugesandt.
Weitere Informationen zu temporären Lizenzen: https://purchase.groupdocs.com/temporary-license/.
Unterstützte Dateiformate
GroupDocs.Markdown for .NET unterstützt ein breites Spektrum gängiger Unternehmens‑ und E‑Book‑Formate. Die vollständige Liste der unterstützten Erweiterungen:
- PDF
pdf
- Spreadsheets
.xls,.xlsx,.xlsb,.xlsm,.xlt,.xltx,.xltm,.xlam,.csv,.tsv,.ods,.ots,.fods,.numbers,.sxc
- Word / Rich Text
.doc,.docx,.dot,.dotm,.dotx,.docm,.rtf,.odt,.ott
- Ebooks
.azw3,.mobi,.epub
- Text / Markup / Help
.chm,.xml,.txt
Funktionsweise (Interna — hohe Ebene)
Bei der Verarbeitung eines Dokuments laufen zwei Hauptphasen ab:
-
Extraktion des Dokumentmodells
Das Dokument wird in ein In‑Memory‑Objektmodell geparst, das strukturelle Elemente (Absätze, Überschriften, Listen, Tabellen, Bilder, Fußnoten, Anmerkungen usw.) repräsentiert. Der Parser bemüht sich, die Semantik zu bewahren (z. B. Listennestungen, Tabellenzellen und Bildunterschriften). -
Markdown‑Generierung
Das Objektmodell wird durchlaufen und gemäß konfigurierbarer Konvertierungsoptionen (Umgang mit Bildern, Tabellenformatierung, Überschriftenebenen, speziellen Anmerkungen usw.) in Markdown umgewandelt. Das Ergebnis ist eine lesbare, semantisch bedeutungsvolle Markdown‑Datei, die bereit für die Indizierung durch Ihre RAG‑Pipeline ist.
Export‑Beispiel
Der obige Code‑Beispiel zeigt, wie ein DOCX nach Markdown exportiert wird. Nehmen wir dieses Beispiel und betrachten die Quell‑ und Ausgabedateien als Demonstration.
Quell‑DOCX
Die Quelldatei rich-text-formatting.docx enthält verschiedene Inhaltsblöcke und ist stark formatiert, um die wichtigsten semantischen Elemente hervorzuheben.
Ausgabe‑Markdown
Der Ausgabebestandteil von rich-text-formatting.md wird unten bereitgestellt und zeigt, wie unterschiedliche Formatierungselemente in der erzeugten Markdown‑Datei dargestellt werden.
This document contains a variety of formatted elements that are used to test document rendering quality during file conversion
# <a name="_toc76372684"></a>**Font Formatting**
Source Sans Pro Light, 14 pt.
Simple text in Times New Roman 12 followed by an empty paragraph<sub>subscript</sub> and<sup>superscript</sup>.
Various characters: ‘ “ & < > £ ¥ § ¨ © ª « ® » ¼
Paragraph with multiple segments of text formatted in different fonts, sizes and colors. Very different sizes and colors including **bold**, *italic*, underline and 1 2 3 4 5 ~~strikethrough~~. Make sure that the lines wrapped in the same way in Word and in Pdf.
This text has shading and highlighting and borders, and it is supported.
# <a name="_toc76372685"></a>**Paragraph Formatting**
Paragraph shading should not form empty gaps even with spacing 12 after.
Centered paragraph with a line break had a problem.\
Centered paragraph with a line break had a problem.
Right aligned paragraphs must be right aligned properly.
Right aligned paragraph with line break works well.\
Right aligned paragraph with line break works well.
This paragraph has a border.
Right aligned condensed text had a problem.
Right aligned expanded text had a problem.
Spacing after and before do not add up, just the greater is used. This paragraph has 12 after. Also, when indents are different, the shading does not join.
This paragraph has 12 before, but in total there is only 12 above. Also note that shading belongs to the paragraph at the top and shading of this paragraph does not go down unless next paragraph has shading too. There are 24 points below.
There are 24 points above, but the gap between this and previous paragraph is only 24.
This paragraph is a test for double line spacing. This paragraph is a test for double line spacing. It also have 0.5” for the first line.
This is a test for 1.5 line spacing. This is a test for 1.5 line spacing. Also has -0.5” indent for the first line.
This paragraph has a page break
and centered. It actually creates two paragraphs.
This is a test for Exactly 20 points of spacing. This is a test for Exactly 20 points of spacing. TTTTTT (20, 22, 24, 26, 28, 30).
There is a continuous section break after this line.
This line is in the new section. Next here is an empty section.
This line is in the fourth section.
# <a name="_toc76372686"></a>**Paragraph Justify**
This is a justified paragraph with a single segment. 111111111111111111111111111111111111111111.
Also a justified **paragraph** reset to left because of multiple segments. 111111111111111111111111111111111111111111.
# **Non-English Characters**
Wingdings: (x, Symbol: WÄ
Russian: Теперь немного по русски.
# <a name="_toc76372687"></a>**Tables**
|Cell 1.1 Left|Cell 1.2 Right|||
| :- | -: | :- | :- |
|Cell 2.1 Centered vertically|Cell 2.2 with background|Cell 2.3 with line break<br>and coloured border.||
|Cell 3.1 Bottom vertically|<p>Cell 3.2</p><p>Centered</p><p>Horizontally</p>|Cell 3.3 No border||
|Left red, blue top, green right and yellow bottom.|
| :- |
|Table with left indent and merged cells.||||
| :- | :- | :- | :- |
|||||
|||||
**Cell padding etc.**
|<p>Cell padding.</p><p>Top: 0.1, bottom 0.2</p><p>Left: 0.5, Right 0.4</p>|Zero padding on all sides, right aligned.|
| :- | -: |
|Outer 1.1|Outer 1.2. There is a nested table here||
| :- | :-: | -: |
|**Nested 1.1**|**Nested 1.2**|
| :- | :- |
|||Outer 1.3|
| :- | :-: | -: |
#
# <a name="_toc76372688"></a>**Lists**
**Numbered list:**
1. Item 1
1. Item 2
1. Item 2.1
1. Item 2.2
1. Item 3
**Bulleted list:**
- Item 1
- Item 2
- Item 2.1
- Item 2.2
- Item 3
#
# <a name="_toc76372689"></a>**Images**
This section starts from a new page.
**Ellipse text**
There is an image in a black border in the top right corner, but it will drop down into the text. There is also a transparent ellipse with text that overlaps the picture.
Inline JPEG in a separate paragraph.

Inline GIF scaled 50% and WMF scaled 25% in a paragraph. This text is before the image and  this text is after the image.
Images in a table. Left and right aligned.
|||
| :- | -: |
Inline text box  is here and inline ellipse  is here.
New section that starts from a new page is here.
It has portrait orientation and margins.
# <a name="_toc76372690"></a>**Fields**
Merge field «FirstName»
Page number 5
Hyperlink [Aspose.com](http://www.aspose.com)
TOC
[Font Formatting 1](#_toc76372684)
[Paragraph Formatting 1](#_toc76372685)
[Non-English Characters 2](#_toc76372686)
[Tables 2](#_toc76372687)
[Lists 2](#_toc76372688)
[Images 4](#_toc76372689)
[Fields 5](#_toc76372690)
# **Form Fields**
Edit <a name="text1"></a>test text
Checkbox <a name="check1"></a>
Combobox <a name="dropdown1"></a>
# **Footnotes and Endnotes**
This line has a footnote at the end.[^1]
This line has an endnote at the end.[^2]
[^1]: Footnote 1.
[^2]: Endnote 1.
Zusammenfassung
GroupDocs.Markdown for .NET hilft Ihnen, ein breites Spektrum von Dokumentformaten in semantisches Markdown zu konvertieren, das für LLM + RAG‑Systeme bereitsteht. Es bewahrt Dokumentstruktur und Bedeutung, läuft vor Ort und unterstützt gängige Unternehmensformate — was es zu einer praktischen Wahl für Organisationen macht, die große Dokumentsammlungen für die KI‑Nutzung vorbereiten müssen.
Weiterführende Informationen
- Produkt‑Startseite: https://products.groupdocs.com/markdown/net/
- Dokumentation: https://docs.groupdocs.com/markdown/net/
- Lizenzinformationen: https://about.groupdocs.com/legal/
- Downloads: https://releases.groupdocs.com/markdown/net/
Support & Feedback
Für Fragen oder technische Unterstützung nutzen Sie bitte unser Free Support Forum — wir helfen Ihnen gern.