
Haz que tus documentos corporativos estén listos para IA — de forma fiable, local y semánticamente.
Es bastante común que las organizaciones mantengan su documentación en formatos PDF, DOCX, XLSX y ePub. Mientras que los LLM (modelos de lenguaje grande) funcionan bien con HTML o texto plano, estos formatos de documento nativos necesitan conversión antes de poder usarse eficazmente en canalizaciones LLM + RAG donde queremos conversar con un documento o un conjunto de documentos.
LLM (Large Language Model) — un modelo de IA pre‑entrenado que genera texto y respuestas basándose en grandes corpora de texto.
RAG (Retrieval‑Augmented Generation) — un enfoque que combina un LLM con una base de conocimientos externa (por ejemplo, documentos corporativos) para que el modelo pueda recuperar y razonar sobre el contenido del dominio.
El siguiente diagrama de secuencia ilustra los pasos típicos involucrados en generar una respuesta a una pregunta:
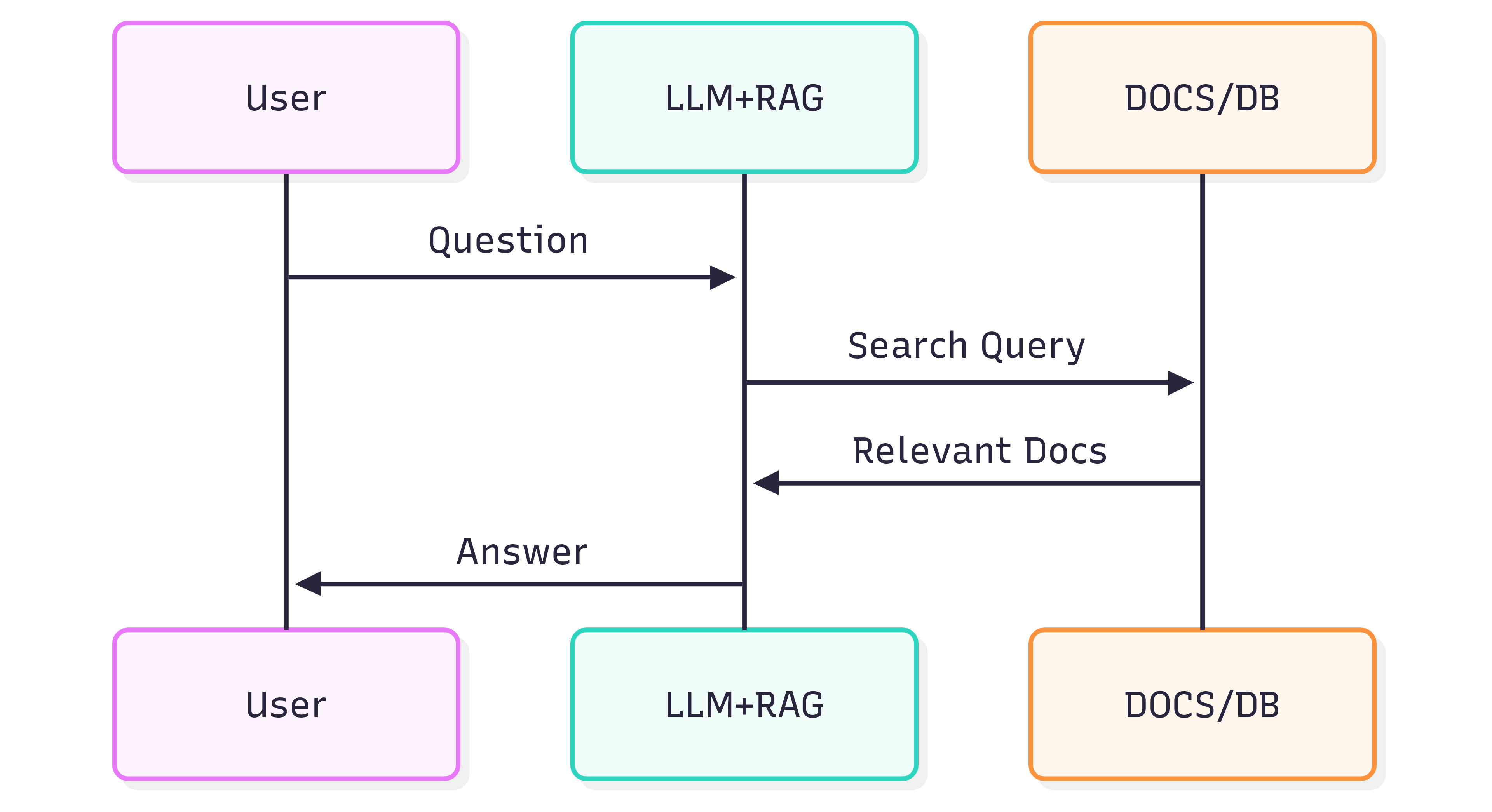
La calidad de las respuestas que obtienes de un Sistema (LLM + RAG) depende tanto del propio Sistema como de qué tan bien los documentos fuente preservan su estructura y significado al alimentarse en la canalización de recuperación.
El problema
El formato de los documentos no es solo visual — lleva semántica. Títulos, listas, tablas, énfasis en negrita/cursiva, pies de foto e imágenes en línea transmiten significado que ayuda a un LLM a comprender el contexto. Convertir documentos de forma ingenua (por ejemplo, usando OCR que trata cada página como una imagen plana) a menudo pierde esa semántica. Como resultado, la recuperación RAG y las respuestas posteriores del LLM pueden volverse inexactas o ruidosas.
El OCR puede ayudar con documentos escaneados, pero con frecuencia elimina la estructura (listas divididas entre páginas, bordes de tabla mal interpretados, anotaciones perdidas). Además, añade costo y sobrecarga de infraestructura al procesar grandes archivos.
La solución
Un enfoque alternativo es analizar los documentos con conciencia estructural y exportar esa estructura a un formato semántico y amigable para LLM — Markdown. Markdown es ligero, ampliamente compatible y preserva títulos, listas, tablas, bloques de código, énfasis, pies de foto y referencias de imágenes — exactamente las características que mejoran la calidad de la recuperación.
GroupDocs.Markdown for .NET convierte formatos de documento populares (PDF, DOCX, XLSX, ePub y más) en Markdown limpio y semántico, apto para ingestión en sistemas RAG. Es una biblioteca .NET on‑premise, por lo que todo el procesamiento ocurre dentro de tu entorno — sin servicios externos, sin fugas de datos y sin dependencia de GPUs remotas.
Cómo empezar
GroupDocs.Markdown for .NET está disponible como paquete NuGet, y también como descargas MSI y ZIP.
Instala el paquete NuGet con la CLI de .NET:
dotnet add package GroupDocs.Markdown
O descarga instaladores y ensamblados desde la página oficial de descargas: https://releases.groupdocs.com/markdown/net/
Ejemplo de uso (añade a Program.cs):
// Import the namespace
using GroupDocs.Markdown;
// Set the license (optional for evaluation)
License.Set("GroupDocs.Markdown.lic");
// Instantiate the converter for a source document
var converter = new MarkdownConverter("rich-text-formatting.docx");
// Convert and save output to file
converter.Convert("rich-text-formatting.md");
El archivo rich-text-formatting.md convertido se guardará en la misma carpeta que tu aplicación.
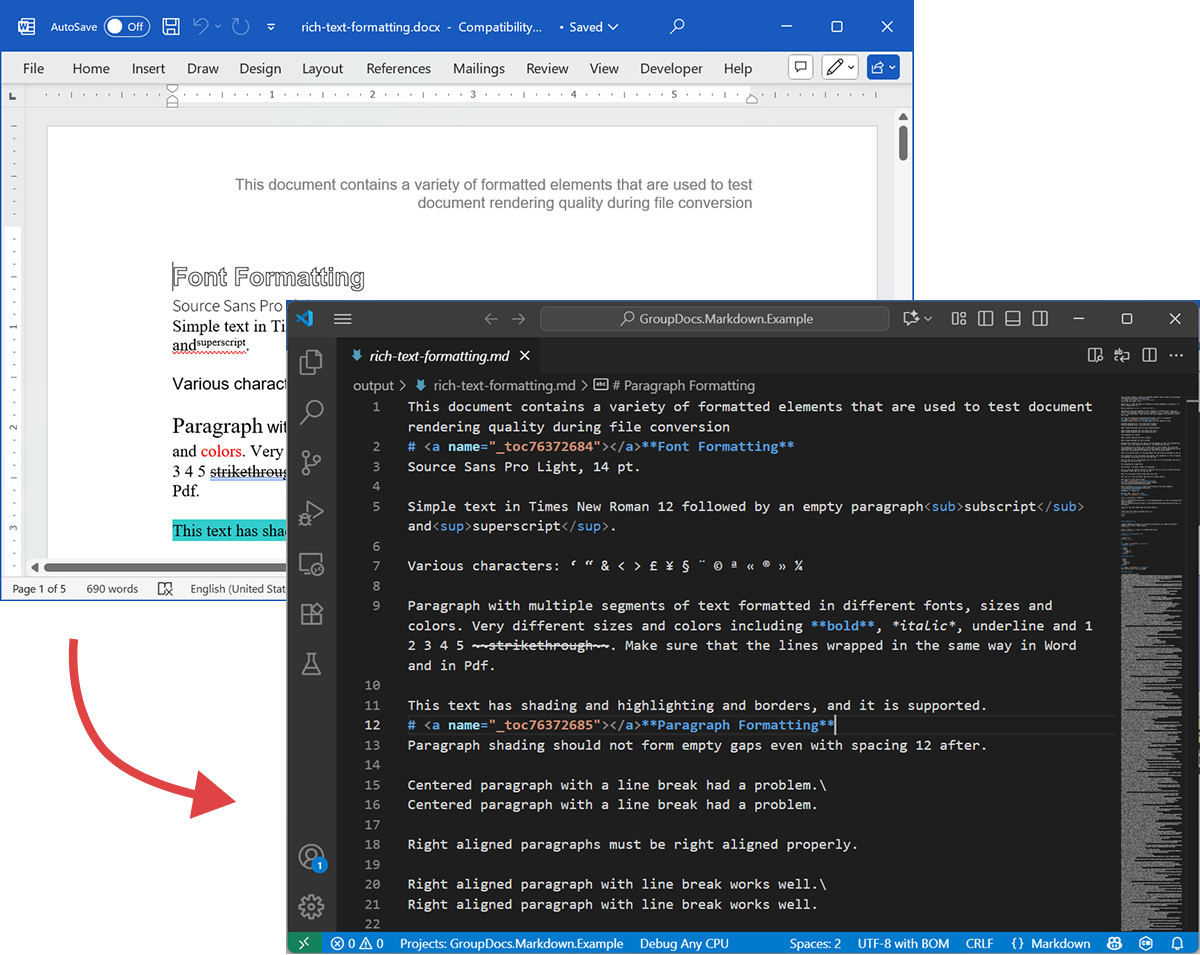
La siguiente captura muestra el archivo DOCX de entrada y el Markdown de salida.
Si lo ejecutas sin una licencia, el modo de evaluación procesará un número limitado de páginas (por ejemplo, las tres primeras). Para probar el producto completo, solicita una licencia temporal.
Para solicitar una licencia temporal, abre el Purchase Wizard, proporciona tus datos de contacto y haz clic en Get a temporary license en el paso Contact Details. La licencia temporal se enviará por correo electrónico.
Obtén más información sobre licencias temporales: https://purchase.groupdocs.com/temporary-license/.
Formatos de archivo compatibles
GroupDocs.Markdown for .NET admite un amplio conjunto de formatos empresariales y de libros electrónicos. La lista completa de extensiones compatibles:
- PDF
pdf
- Hojas de cálculo
.xls,.xlsx,.xlsb,.xlsm,.xlt,.xltx,.xltm,.xlam,.csv,.tsv,.ods,.ots,.fods,.numbers,.sxc
- Word / Texto enriquecido
.doc,.docx,.dot,.dotm,.dotx,.docm,.rtf,.odt,.ott
- Libros electrónicos
.azw3,.mobi,.epub
- Texto / Marcado / Ayuda
.chm,.xml,.txt
Cómo funciona (internos — alto nivel)
Cuando se procesa un documento, ocurren dos fases principales:
-
Extracción del modelo del documento
El documento se analiza en un modelo de objetos en memoria que representa los elementos estructurales (párrafos, títulos, listas, tablas, imágenes, notas al pie, anotaciones, etc.). El analizador se esfuerza por preservar la semántica (por ejemplo, anidamiento de listas, celdas de tabla y pies de foto). -
Generación de Markdown
El modelo de objetos se recorre y se convierte a Markdown según opciones de conversión configurables (cómo manejar imágenes, formato de tablas, niveles de títulos, anotaciones especiales, etc.). El resultado es un archivo Markdown legible y semánticamente significativo, listo para ser indexado por tu canalización RAG.
Ejemplo de exportación
El ejemplo de código anterior muestra cómo exportar DOCX a Markdown. Tomemos este ejemplo y veamos los archivos de origen y salida como demostración.
DOCX de origen
El archivo de origen rich-text-formatting.docx contiene varios bloques de contenido y está fuertemente formateado para resaltar los principales elementos semánticos.
Markdown de salida
El contenido de salida de rich-text-formatting.md se muestra a continuación, ilustrando cómo se representan diferentes elementos de formato en el archivo Markdown generado.
This document contains a variety of formatted elements that are used to test document rendering quality during file conversion
# <a name="_toc76372684"></a>**Font Formatting**
Source Sans Pro Light, 14 pt.
Simple text in Times New Roman 12 followed by an empty paragraph<sub>subscript</sub> and<sup>superscript</sup>.
Various characters: ‘ “ & < > £ ¥ § ¨ © ª « ® » ¼
Paragraph with multiple segments of text formatted in different fonts, sizes and colors. Very different sizes and colors including **bold**, *italic*, underline and 1 2 3 4 5 ~~strikethrough~~. Make sure that the lines wrapped in the same way in Word and in Pdf.
This text has shading and highlighting and borders, and it is supported.
# <a name="_toc76372685"></a>**Paragraph Formatting**
Paragraph shading should not form empty gaps even with spacing 12 after.
Centered paragraph with a line break had a problem.\
Centered paragraph with a line break had a problem.
Right aligned paragraphs must be right aligned properly.
Right aligned paragraph with line break works well.\
Right aligned paragraph with line break works well.
This paragraph has a border.
Right aligned condensed text had a problem.
Right aligned expanded text had a problem.
Spacing after and before do not add up, just the greater is used. This paragraph has 12 after. Also, when indents are different, the shading does not join.
This paragraph has 12 before, but in total there is only 12 above. Also note that shading belongs to the paragraph at the top and shading of this paragraph does not go down unless next paragraph has shading too. There are 24 points below.
There are 24 points above, but the gap between this and previous paragraph is only 24.
This paragraph is a test for double line spacing. This paragraph is a test for double line spacing. It also have 0.5” for the first line.
This is a test for 1.5 line spacing. This is a test for 1.5 line spacing. Also has -0.5” indent for the first line.
This paragraph has a page break
and centered. It actually creates two paragraphs.
This is a test for Exactly 20 points of spacing. This is a test for Exactly 20 points of spacing. TTTTTT (20, 22, 24, 26, 28, 30).
There is a continuous section break after this line.
This line is in the new section. Next here is an empty section.
This line is in the fourth section.
# <a name="_toc76372686"></a>**Paragraph Justify**
This is a justified paragraph with a single segment. 111111111111111111111111111111111111111111.
Also a justified **paragraph** reset to left because of multiple segments. 111111111111111111111111111111111111111111.
# **Non-English Characters**
Wingdings: (x, Symbol: WÄ
Russian: Теперь немного по русски.
# <a name="_toc76372687"></a>**Tables**
|Cell 1.1 Left|Cell 1.2 Right|||
| :- | -: | :- | :- |
|Cell 2.1 Centered vertically|Cell 2.2 with background|Cell 2.3 with line break<br>and coloured border.||
|Cell 3.1 Bottom vertically|<p>Cell 3.2</p><p>Centered</p><p>Horizontally</p>|Cell 3.3 No border||
|Left red, blue top, green right and yellow bottom.|
| :- |
|Table with left indent and merged cells.||||
| :- | :- | :- | :- |
|||||
|||||
**Cell padding etc.**
|<p>Cell padding.</p><p>Top: 0.1, bottom 0.2</p><p>Left: 0.5, Right 0.4</p>|Zero padding on all sides, right aligned.|
| :- | -: |
|Outer 1.1|Outer 1.2. There is a nested table here||
| :- | :-: | -: |
|**Nested 1.1**|**Nested 1.2**|
| :- | :- |
|||Outer 1.3|
| :- | :-: | -: |
#
# <a name="_toc76372688"></a>**Lists**
**Numbered list:**
1. Item 1
1. Item 2
1. Item 2.1
1. Item 2.2
1. Item 3
**Bulleted list:**
- Item 1
- Item 2
- Item 2.1
- Item 2.2
- Item 3
#
# <a name="_toc76372689"></a>**Images**
This section starts from a new page.
**Ellipse text**
There is an image in a black border in the top right corner, but it will drop down into the text. There is also a transparent ellipse with text that overlaps the picture.
Inline JPEG in a separate paragraph.

Inline GIF scaled 50% and WMF scaled 25% in a paragraph. This text is before the image and  this text is after the image.
Images in a table. Left and right aligned.
|||
| :- | -: |
Inline text box  is here and inline ellipse  is here.
New section that starts from a new page is here.
It has portrait orientation and margins.
# <a name="_toc76372690"></a>**Fields**
Merge field «FirstName»
Page number 5
Hyperlink [Aspose.com](http://www.aspose.com)
TOC
[Font Formatting 1](#_toc76372684)
[Paragraph Formatting 1](#_toc76372685)
[Non-English Characters 2](#_toc76372686)
[Tables 2](#_toc76372687)
[Lists 2](#_toc76372688)
[Images 4](#_toc76372689)
[Fields 5](#_toc76372690)
# **Form Fields**
Edit <a name="text1"></a>test text
Checkbox <a name="check1"></a>
Combobox <a name="dropdown1"></a>
# **Footnotes and Endnotes**
This line has a footnote at the end.[^1]
This line has an endnote at the end.[^2]
[^1]: Footnote 1.
[^2]: Endnote 1.
Resumen
GroupDocs.Markdown for .NET te ayuda a convertir una amplia gama de formatos de documento en Markdown semántico listo para sistemas LLM + RAG. Preserva la estructura y el significado del documento, se ejecuta on‑premise y admite formatos empresariales comunes, lo que lo convierte en una opción práctica para organizaciones que necesitan preparar grandes colecciones de documentos para el consumo de IA.
Más información
- Página del producto: https://products.groupdocs.com/markdown/net/
- Documentación: https://docs.groupdocs.com/markdown/net/
- Información de licencias: https://about.groupdocs.com/legal/
- Descargas: https://releases.groupdocs.com/markdown/net/
Soporte y comentarios
Para preguntas o asistencia técnica, utiliza nuestro Free Support Forum — estaremos encantados de ayudar.