
Buat dokumen korporat Anda siap AI — andal, di tempat, dan semantik.
Itu adalah kasus yang cukup umum ketika organisasi menyimpan dokumentasi mereka dalam format PDF, DOCX, XLSX, dan ePub. Sementara LLM (large language models) bekerja dengan baik pada HTML atau teks biasa, format dokumen asli ini memerlukan konversi sebelum dapat digunakan secara efektif dalam pipeline LLM + RAG di mana kami ingin mengobrol dengan sebuah dokumen atau sekumpulan dokumen.
LLM (Large Language Model) — model AI yang telah dilatih sebelumnya yang menghasilkan teks dan jawaban berdasarkan korpus teks yang besar.
RAG (Retrieval‑Augmented Generation) — pendekatan yang menggabungkan LLM dengan basis pengetahuan eksternal (misalnya, dokumen korporat) sehingga model dapat mengambil dan menalar atas konten domain.
Diagram urutan berikut menggambarkan langkah‑langkah tipikal yang terlibat dalam menghasilkan jawaban atas sebuah pertanyaan:
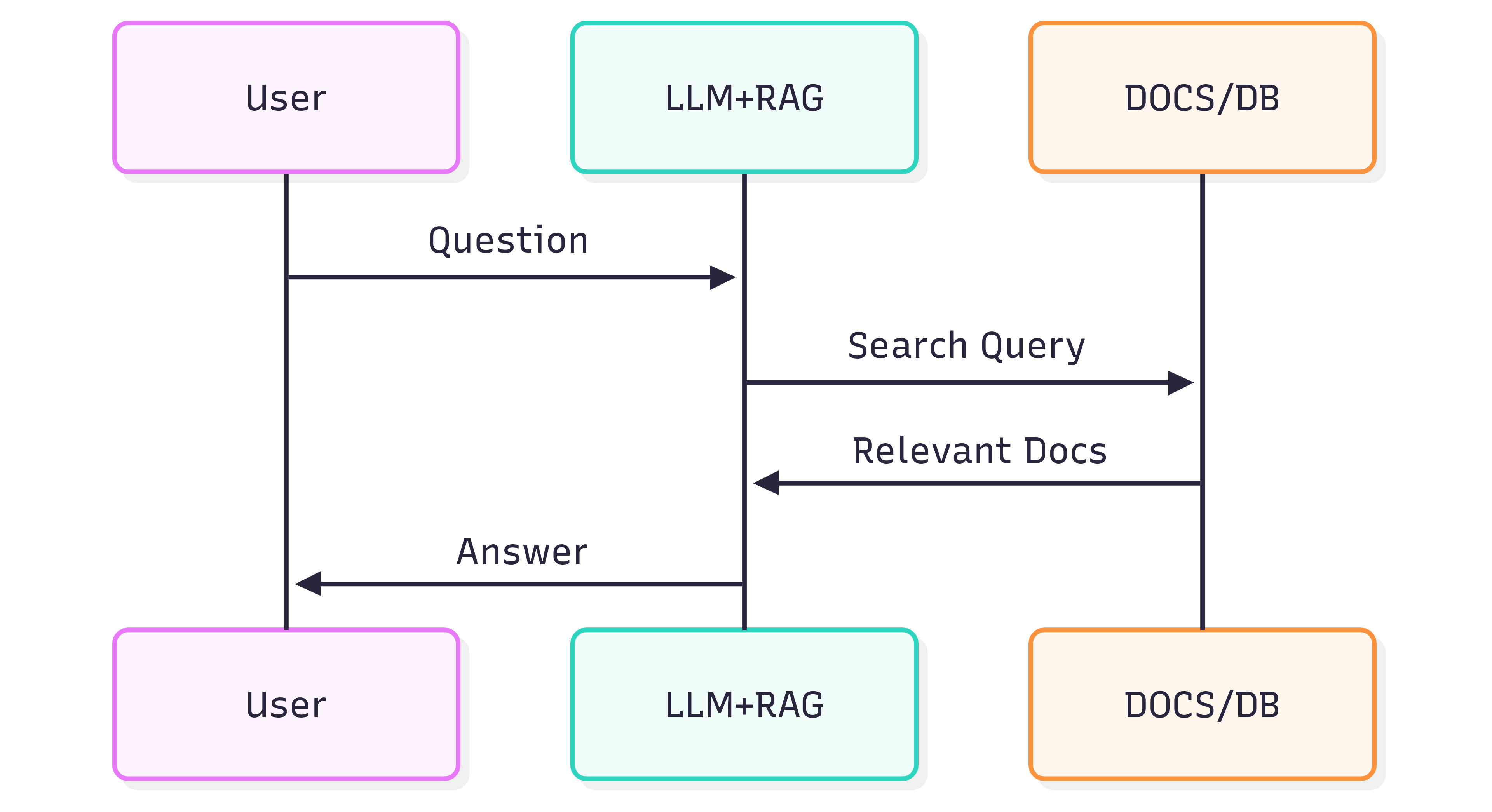
Kualitas jawaban yang Anda dapatkan dari Sistem (LLM + RAG) bergantung pada Sistem itu sendiri serta seberapa baik dokumen sumber mempertahankan struktur dan maknanya ketika dimasukkan ke dalam pipeline pengambilan.
Masalah
Pemformatan dokumen bukan hanya visual — ia membawa semantik. Heading, daftar, tabel, penekanan tebal/miring, caption, dan gambar inline semuanya menyampaikan makna yang membantu LLM memahami konteks. Mengonversi dokumen secara sembarangan (misalnya, menggunakan OCR yang memperlakukan setiap halaman sebagai gambar datar) sering kali kehilangan semantik tersebut. Akibatnya, pengambilan RAG dan jawaban LLM di hilir dapat menjadi tidak akurat atau berisik.
OCR dapat membantu untuk dokumen yang dipindai tetapi sering menghilangkan struktur (daftar terpisah antar halaman, batas tabel disalahartikan, anotasi hilang). OCR juga menambah biaya dan beban infrastruktur saat memproses arsip besar.
Solusi
Pendekatan alternatif adalah mem‑parse dokumen dengan kesadaran struktural dan mengekspor struktur tersebut ke format yang semantik dan ramah LLM — Markdown. Markdown ringan, didukung secara luas, dan mempertahankan heading, daftar, tabel, blok kode, penekanan, caption, serta referensi gambar — tepatnya fitur‑fitur yang meningkatkan kualitas pengambilan.
GroupDocs.Markdown for .NET mengonversi format dokumen populer (PDF, DOCX, XLSX, ePub, dan lainnya) menjadi Markdown bersih dan semantik yang cocok untuk di‑ingest ke dalam sistem RAG. Ini adalah perpustakaan .NET yang dijalankan di‑premise, sehingga semua pemrosesan terjadi di dalam lingkungan Anda — tanpa layanan eksternal, tanpa kebocoran data, dan tanpa ketergantungan pada GPU remote.
Cara Memulai
GroupDocs.Markdown for .NET tersedia sebagai paket NuGet, serta unduhan MSI dan ZIP.
Instal paket NuGet dengan .NET CLI:
dotnet add package GroupDocs.Markdown
Atau unduh installer dan assembly dari halaman unduhan resmi: https://releases.groupdocs.com/markdown/net/
Contoh penggunaan (tambahkan ke Program.cs):
// Import the namespace
using GroupDocs.Markdown;
// Set the license (optional for evaluation)
License.Set("GroupDocs.Markdown.lic");
// Instantiate the converter for a source document
var converter = new MarkdownConverter("rich-text-formatting.docx");
// Convert and save output to file
converter.Convert("rich-text-formatting.md");
File rich-text-formatting.md yang telah dikonversi akan disimpan di folder yang sama dengan aplikasi Anda.
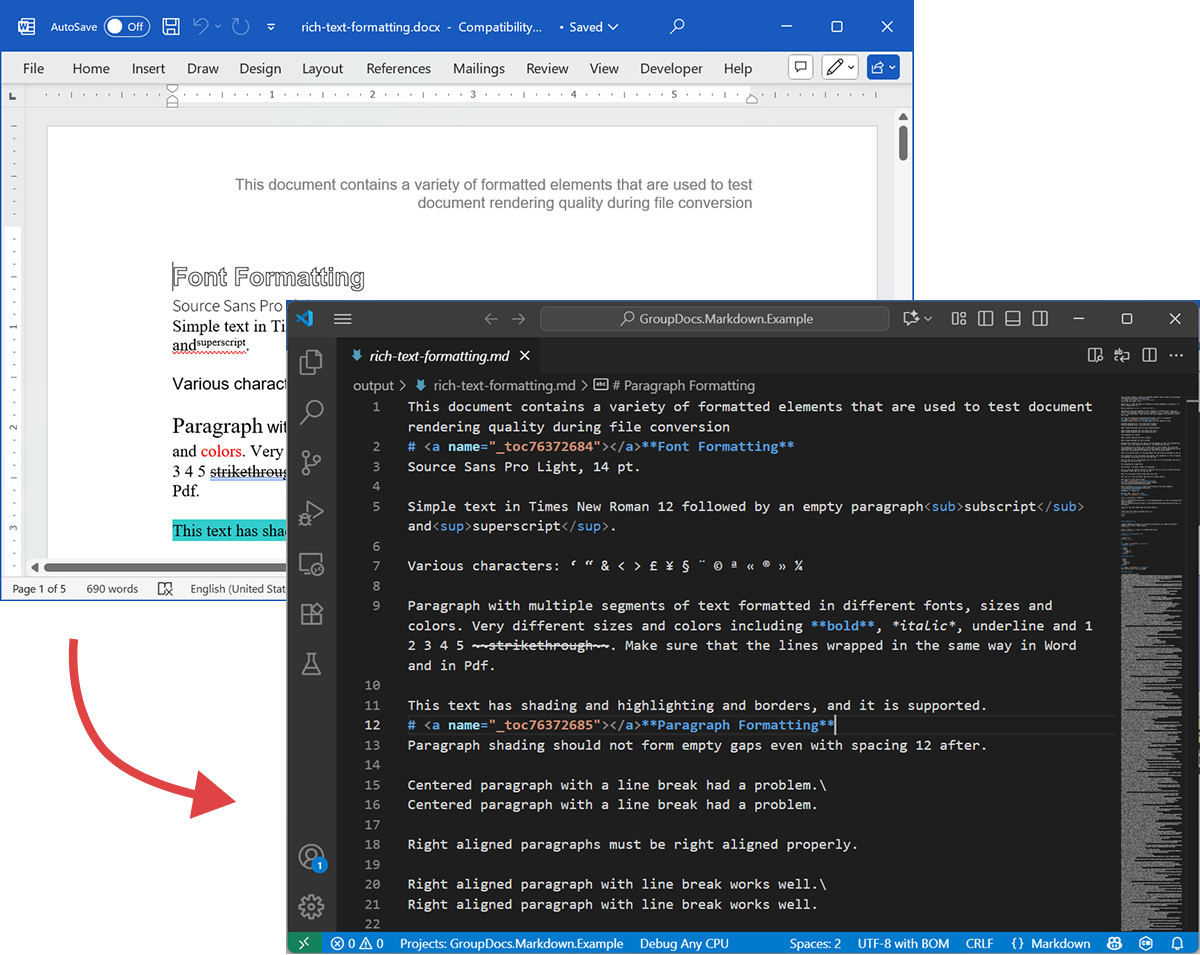
Screenshot berikut menunjukkan file DOCX input dan Markdown output.
Jika Anda menjalankan tanpa lisensi, mode evaluasi akan memproses sejumlah halaman terbatas (misalnya, tiga halaman pertama). Untuk mencoba produk penuh, minta lisensi sementara.
Untuk meminta lisensi sementara, buka Purchase Wizard, isi detail kontak, dan klik Get a temporary license pada langkah Contact Details. Lisensi sementara akan dikirimkan ke email Anda.
Pelajari lebih lanjut tentang lisensi sementara: https://purchase.groupdocs.com/temporary-license/.
Format file yang didukung
GroupDocs.Markdown for .NET mendukung beragam format umum perusahaan dan ebook. Daftar lengkap ekstensi yang didukung:
- PDF
pdf
- Spreadsheet
.xls,.xlsx,.xlsb,.xlsm,.xlt,.xltx,.xltm,.xlam,.csv,.tsv,.ods,.ots,.fods,.numbers,.sxc
- Word / Rich Text
.doc,.docx,.dot,.dotm,.dotx,.docm,.rtf,.odt,.ott
- Ebook
.azw3,.mobi,.epub
- Teks / Markup / Bantuan
.chm,.xml,.txt
Cara Kerja (internal — tingkat tinggi)
Saat sebuah dokumen diproses, dua fase utama terjadi:
-
Ekstraksi model dokumen
Dokumen diparse menjadi model objek dalam memori yang mewakili elemen struktural (paragraf, heading, daftar, tabel, gambar, catatan kaki, anotasi, dll.). Parser berusaha mempertahankan semantik (misalnya, nesting daftar, sel tabel, dan caption gambar). -
Generasi Markdown
Model objek dilalui dan dikonversi ke Markdown sesuai opsi konversi yang dapat dikonfigurasi (cara menangani gambar, format tabel, level heading, anotasi khusus, dll.). Hasilnya adalah file Markdown yang dapat dibaca, bermakna secara semantik, dan siap diindeks oleh pipeline RAG Anda.
Contoh Ekspor
Contoh kode di atas menunjukkan cara mengekspor DOCX ke Markdown. Mari kita ambil contoh kode ini dan melihat file sumber serta output sebagai demonstrasi.
DOCX Sumber
File sumber rich-text-formatting.docx berisi berbagai blok konten dan diformat secara intensif untuk menyoroti elemen semantik utama.
Markdown Output
Konten output dari rich-text-formatting.md disediakan di bawah, menunjukkan bagaimana elemen pemformatan yang berbeda direpresentasikan dalam file Markdown yang dihasilkan.
This document contains a variety of formatted elements that are used to test document rendering quality during file conversion
# <a name="_toc76372684"></a>**Font Formatting**
Source Sans Pro Light, 14 pt.
Simple text in Times New Roman 12 followed by an empty paragraph<sub>subscript</sub> and<sup>superscript</sup>.
Various characters: ‘ “ & < > £ ¥ § ¨ © ª « ® » ¼
Paragraph with multiple segments of text formatted in different fonts, sizes and colors. Very different sizes and colors including **bold**, *italic*, underline and 1 2 3 4 5 ~~strikethrough~~. Make sure that the lines wrapped in the same way in Word and in Pdf.
This text has shading and highlighting and borders, and it is supported.
# <a name="_toc76372685"></a>**Paragraph Formatting**
Paragraph shading should not form empty gaps even with spacing 12 after.
Centered paragraph with a line break had a problem.\
Centered paragraph with a line break had a problem.
Right aligned paragraphs must be right aligned properly.
Right aligned paragraph with line break works well.\
Right aligned paragraph with line break works well.
This paragraph has a border.
Right aligned condensed text had a problem.
Right aligned expanded text had a problem.
Spacing after and before do not add up, just the greater is used. This paragraph has 12 after. Also, when indents are different, the shading does not join.
This paragraph has 12 before, but in total there is only 12 above. Also note that shading belongs to the paragraph at the top and shading of this paragraph does not go down unless next paragraph has shading too. There are 24 points below.
There are 24 points above, but the gap between this and previous paragraph is only 24.
This paragraph is a test for double line spacing. This paragraph is a test for double line spacing. It also have 0.5” for the first line.
This is a test for 1.5 line spacing. This is a test for 1.5 line spacing. Also has -0.5” indent for the first line.
This paragraph has a page break
and centered. It actually creates two paragraphs.
This is a test for Exactly 20 points of spacing. This is a test for Exactly 20 points of spacing. TTTTTT (20, 22, 24, 26, 28, 30).
There is a continuous section break after this line.
This line is in the new section. Next here is an empty section.
This line is in the fourth section.
# <a name="_toc76372686"></a>**Paragraph Justify**
This is a justified paragraph with a single segment. 111111111111111111111111111111111111111111.
Also a justified **paragraph** reset to left because of multiple segments. 111111111111111111111111111111111111111111.
# **Non-English Characters**
Wingdings: (x, Symbol: WÄ
Russian: Теперь немного по русски.
# <a name="_toc76372687"></a>**Tables**
|Cell 1.1 Left|Cell 1.2 Right|||
| :- | -: | :- | :- |
|Cell 2.1 Centered vertically|Cell 2.2 with background|Cell 2.3 with line break<br>and coloured border.||
|Cell 3.1 Bottom vertically|<p>Cell 3.2</p><p>Centered</p><p>Horizontally</p>|Cell 3.3 No border||
|Left red, blue top, green right and yellow bottom.|
| :- |
|Table with left indent and merged cells.||||
| :- | :- | :- | :- |
|||||
|||||
**Cell padding etc.**
|<p>Cell padding.</p><p>Top: 0.1, bottom 0.2</p><p>Left: 0.5, Right 0.4</p>|Zero padding on all sides, right aligned.|
| :- | -: |
|Outer 1.1|Outer 1.2. There is a nested table here||
| :- | :-: | -: |
|**Nested 1.1**|**Nested 1.2**|
| :- | :- |
|||Outer 1.3|
| :- | :-: | -: |
#
# <a name="_toc76372688"></a>**Lists**
**Numbered list:**
1. Item 1
1. Item 2
1. Item 2.1
1. Item 2.2
1. Item 3
**Bulleted list:**
- Item 1
- Item 2
- Item 2.1
- Item 2.2
- Item 3
#
# <a name="_toc76372689"></a>**Images**
This section starts from a new page.
**Ellipse text**
There is an image in a black border in the top right corner, but it will drop down into the text. There is also a transparent ellipse with text that overlaps the picture.
Inline JPEG in a separate paragraph.

Inline GIF scaled 50% and WMF scaled 25% in a paragraph. This text is before the image and  this text is after the image.
Images in a table. Left and right aligned.
|||
| :- | -: |
Inline text box  is here and inline ellipse  is here.
New section that starts from a new page is here.
It has portrait orientation and margins.
# <a name="_toc76372690"></a>**Fields**
Merge field «FirstName»
Page number 5
Hyperlink [Aspose.com](http://www.aspose.com)
TOC
[Font Formatting 1](#_toc76372684)
[Paragraph Formatting 1](#_toc76372685)
[Non-English Characters 2](#_toc76372686)
[Tables 2](#_toc76372687)
[Lists 2](#_toc76372688)
[Images 4](#_toc76372689)
[Fields 5](#_toc76372690)
# **Form Fields**
Edit <a name="text1"></a>test text
Checkbox <a name="check1"></a>
Combobox <a name="dropdown1"></a>
# **Footnotes and Endnotes**
This line has a footnote at the end.[^1]
This line has an endnote at the end.[^2]
[^1]: Footnote 1.
[^2]: Endnote 1.
Ringkasan
GroupDocs.Markdown for .NET membantu Anda mengonversi berbagai format dokumen menjadi Markdown semantik yang siap untuk sistem LLM + RAG. Ia mempertahankan struktur dan makna dokumen, berjalan di‑premise, dan mendukung format perusahaan umum — menjadikannya pilihan praktis bagi organisasi yang perlu menyiapkan koleksi dokumen besar untuk konsumsi AI.
Pelajari lebih lanjut
- Beranda produk: https://products.groupdocs.com/markdown/net/
- Dokumentasi: https://docs.groupdocs.com/markdown/net/
- Informasi lisensi: https://about.groupdocs.com/legal/
- Unduhan: https://releases.groupdocs.com/markdown/net/
Dukungan & umpan balik
Untuk pertanyaan atau bantuan teknis, silakan gunakan Free Support Forum kami — kami dengan senang hati akan membantu.