
Rendi i tuoi documenti aziendali pronti per l’IA — in modo affidabile, on‑premise e semanticamente.
È un caso piuttosto comune che le organizzazioni conservino la loro documentazione in formati PDF, DOCX, XLSX ed ePub. Mentre i LLM (large language models) funzionano bene con HTML o testo semplice, questi formati di documento nativi necessitano di conversione prima di poter essere usati efficacemente in pipeline LLM + RAG in cui vogliamo conversare con un documento o un insieme di documenti.
LLM (Large Language Model) — un modello AI pre‑addestrato che genera testo e risposte basate su grandi corpora di testo.
RAG (Retrieval‑Augmented Generation) — un approccio che combina un LLM con una base di conoscenza esterna (ad esempio, documenti aziendali) così che il modello possa recuperare e ragionare sul contenuto del dominio.
Il diagramma di sequenza seguente illustra i passaggi tipici coinvolti nella generazione di una risposta a una domanda:
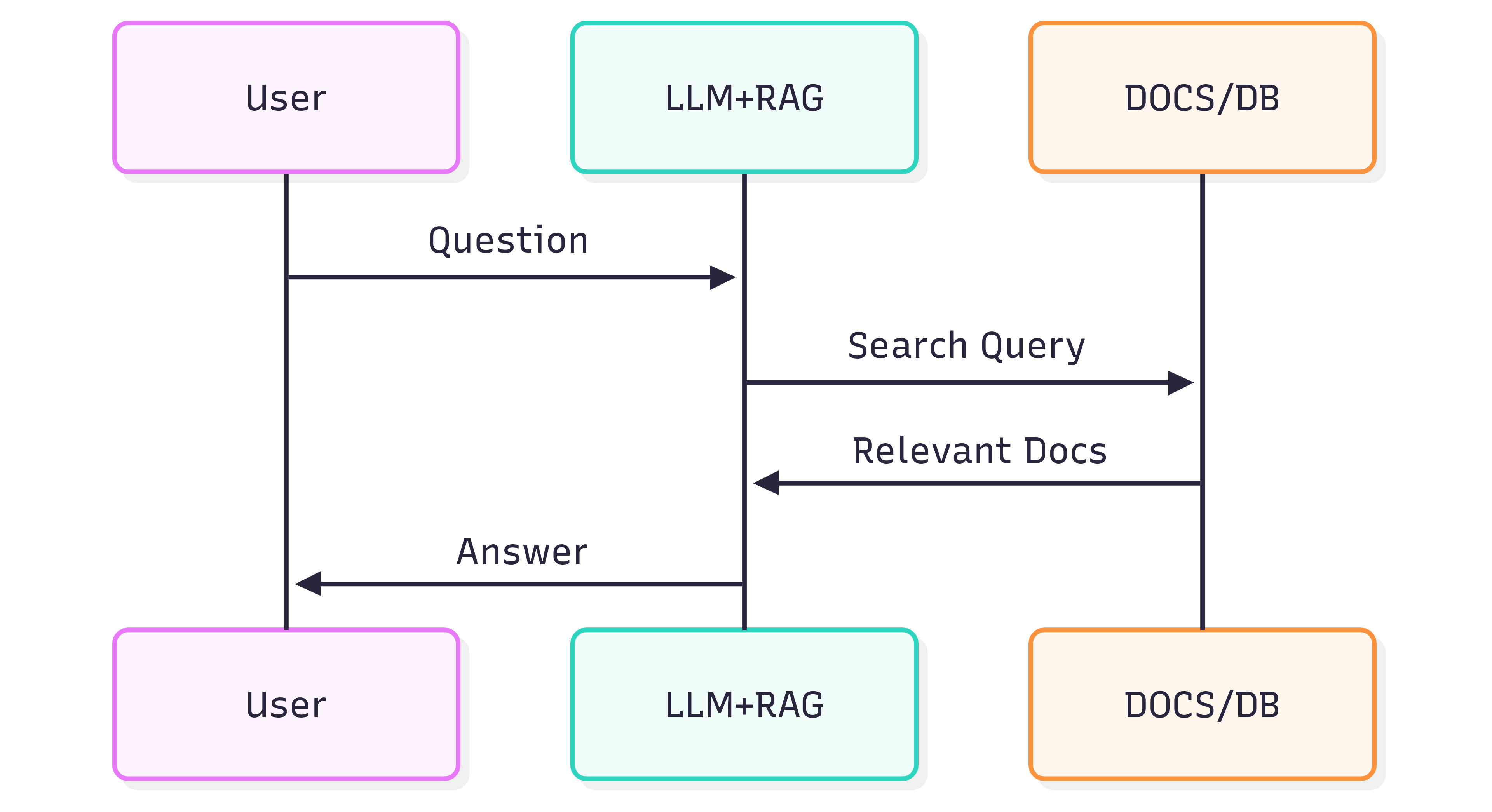
La qualità delle risposte che ottieni da un Sistema (LLM + RAG) dipende sia dal Sistema stesso sia da quanto bene i documenti sorgente preservano la loro struttura e il loro significato quando vengono inseriti nella pipeline di recupero.
Il problema
Il formato dei documenti non è solo visivo — trasporta semantica. Titoli, elenchi, tabelle, enfasi in grassetto/corsivo, didascalie e immagini in linea trasmettono tutti significato che aiuta un LLM a comprendere il contesto. Convertire i documenti in modo ingenuo (ad esempio, usando OCR che tratta ogni pagina come un’immagine piatta) spesso perde queste semantiche. Di conseguenza, il recupero RAG e le risposte LLM a valle possono diventare imprecise o rumorose.
L’OCR può aiutare per i documenti scansionati ma spesso rimuove la struttura (elenchi divisi tra pagine, bordi di tabella interpretati erroneamente, annotazioni perse). Inoltre aggiunge costi e oneri infrastrutturali quando si elaborano grandi archivi.
La soluzione
Un approccio alternativo è analizzare i documenti con consapevolezza strutturale ed esportare tale struttura in un formato semantico e amichevole per LLM — Markdown. Markdown è leggero, ampiamente supportato e preserva titoli, elenchi, tabelle, blocchi di codice, enfasi, didascalie e riferimenti alle immagini — esattamente le caratteristiche che migliorano la qualità del recupero.
GroupDocs.Markdown for .NET converte i formati di documento più popolari (PDF, DOCX, XLSX, ePub e altri) in Markdown pulito e semantico, adatto all’ingestione nei sistemi RAG. È una libreria .NET on‑premise, quindi tutta l’elaborazione avviene all’interno del tuo ambiente — nessun servizio esterno, nessuna perdita di dati e nessuna dipendenza da GPU remote.
Come iniziare
GroupDocs.Markdown for .NET è disponibile come pacchetto NuGet, nonché come download MSI e ZIP.
Installa il pacchetto NuGet con la .NET CLI:
dotnet add package GroupDocs.Markdown
Oppure scarica gli installer e gli assembly dalla pagina ufficiale dei download: https://releases.groupdocs.com/markdown/net/
Esempio di utilizzo (aggiungi a Program.cs):
// Import the namespace
using GroupDocs.Markdown;
// Set the license (optional for evaluation)
License.Set("GroupDocs.Markdown.lic");
// Instantiate the converter for a source document
var converter = new MarkdownConverter("rich-text-formatting.docx");
// Convert and save output to file
converter.Convert("rich-text-formatting.md");
Il file rich-text-formatting.md convertito verrà salvato nella stessa cartella dell’applicazione.
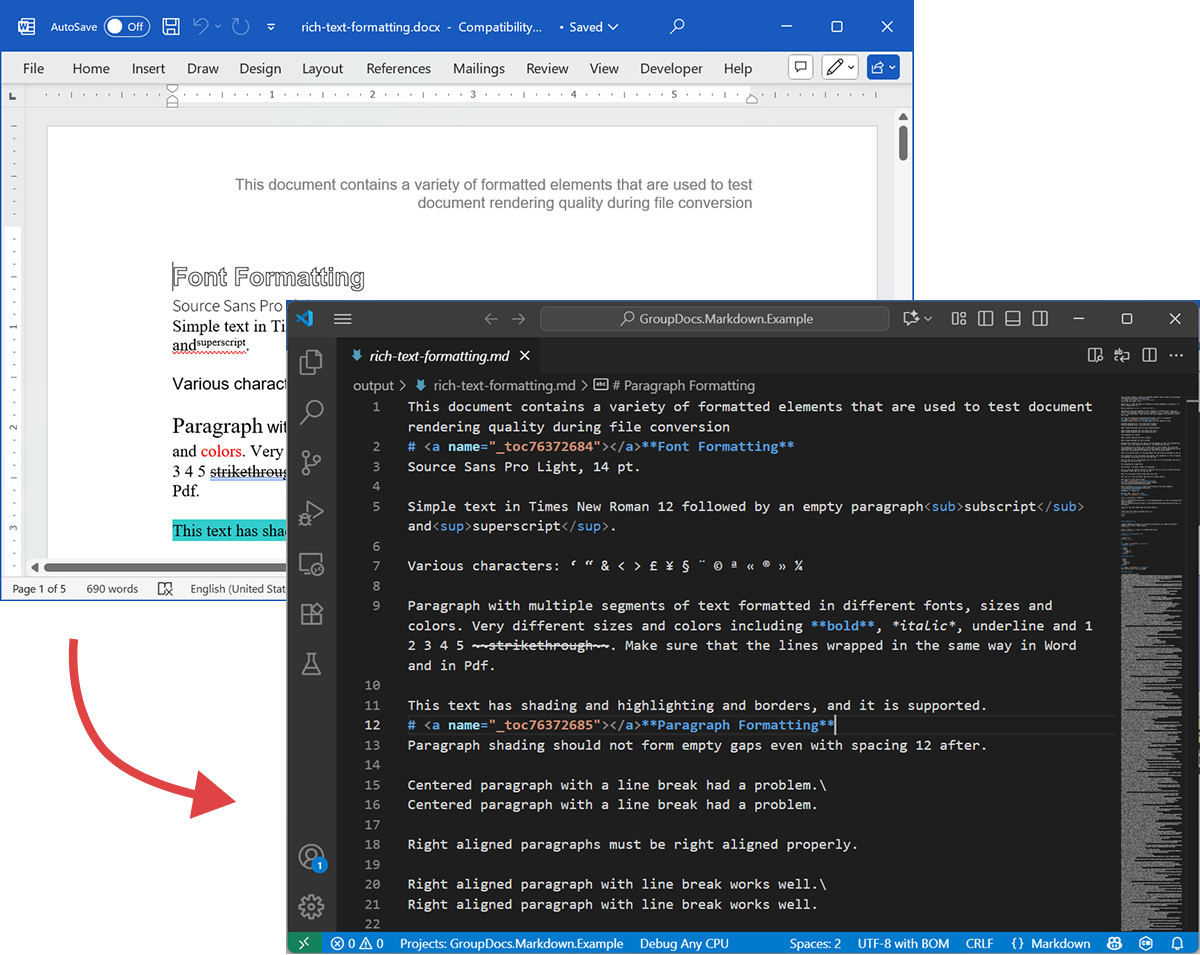
Lo screenshot seguente mostra il file DOCX di input e il Markdown di output.
Se lo esegui senza licenza, la modalità di valutazione elaborerà un numero limitato di pagine (ad esempio, le prime tre pagine). Per provare il prodotto completo, richiedi una licenza temporanea.
Per richiedere una licenza temporanea, apri la Procedura guidata di acquisto, inserisci i dati di contatto e fai clic su Ottieni una licenza temporanea nella fase Dettagli di contatto. La licenza temporanea ti sarà inviata via e‑mail.
Scopri di più sulle licenze temporanee: https://purchase.groupdocs.com/temporary-license/.
Formati di file supportati
GroupDocs.Markdown for .NET supporta un ampio insieme di formati aziendali ed ebook comuni. L’elenco completo delle estensioni supportate:
- PDF
pdf
- Fogli di calcolo
.xls,.xlsx,.xlsb,.xlsm,.xlt,.xltx,.xltm,.xlam,.csv,.tsv,.ods,.ots,.fods,.numbers,.sxc
- Word / Rich Text
.doc,.docx,.dot,.dotm,.dotx,.docm,.rtf,.odt,.ott
- Ebook
.azw3,.mobi,.epub
- Testo / Markup / Help
.chm,.xml,.txt
Come funziona (interni — alto livello)
Quando un documento viene elaborato, si verificano due fasi principali:
-
Estrazione del modello del documento
Il documento viene analizzato in un modello di oggetti in memoria che rappresenta gli elementi strutturali (paragrafi, titoli, elenchi, tabelle, immagini, note a piè di pagina, annotazioni, ecc.). L’analizzatore si sforza di preservare la semantica (ad esempio, nidificazione degli elenchi, celle di tabella e didascalie delle immagini). -
Generazione di Markdown
Il modello di oggetti viene attraversato e convertito in Markdown secondo le opzioni di conversione configurabili (come gestire immagini, formattazione delle tabelle, livelli dei titoli, annotazioni speciali, ecc.). Il risultato è un file Markdown leggibile e semanticamente significativo, pronto per l’indicizzazione da parte della tua pipeline RAG.
Esempio di esportazione
Il codice mostrato sopra dimostra come esportare DOCX in Markdown. Prendiamo questo esempio di codice e osserviamo i file sorgente e di output come dimostrazione.
DOCX di origine
Il file di origine rich-text-formatting.docx contiene vari blocchi di contenuto ed è fortemente formattato per evidenziare gli elementi semantici principali.
Markdown di output
Il contenuto di output di rich-text-formatting.md è fornito di seguito, mostrando come i diversi elementi di formattazione sono rappresentati nel file Markdown generato.
This document contains a variety of formatted elements that are used to test document rendering quality during file conversion
# <a name="_toc76372684"></a>**Font Formatting**
Source Sans Pro Light, 14 pt.
Simple text in Times New Roman 12 followed by an empty paragraph<sub>subscript</sub> and<sup>superscript</sup>.
Various characters: ‘ “ & < > £ ¥ § ¨ © ª « ® » ¼
Paragraph with multiple segments of text formatted in different fonts, sizes and colors. Very different sizes and colors including **bold**, *italic*, underline and 1 2 3 4 5 ~~strikethrough~~. Make sure that the lines wrapped in the same way in Word and in Pdf.
This text has shading and highlighting and borders, and it is supported.
# <a name="_toc76372685"></a>**Paragraph Formatting**
Paragraph shading should not form empty gaps even with spacing 12 after.
Centered paragraph with a line break had a problem.\
Centered paragraph with a line break had a problem.
Right aligned paragraphs must be right aligned properly.
Right aligned paragraph with line break works well.\
Right aligned paragraph with line break works well.
This paragraph has a border.
Right aligned condensed text had a problem.
Right aligned expanded text had a problem.
Spacing after and before do not add up, just the greater is used. This paragraph has 12 after. Also, when indents are different, the shading does not join.
This paragraph has 12 before, but in total there is only 12 above. Also note that shading belongs to the paragraph at the top and shading of this paragraph does not go down unless next paragraph has shading too. There are 24 points below.
There are 24 points above, but the gap between this and previous paragraph is only 24.
This paragraph is a test for double line spacing. This paragraph is a test for double line spacing. It also have 0.5” for the first line.
This is a test for 1.5 line spacing. This is a test for 1.5 line spacing. Also has -0.5” indent for the first line.
This paragraph has a page break
and centered. It actually creates two paragraphs.
This is a test for Exactly 20 points of spacing. This is a test for Exactly 20 points of spacing. TTTTTT (20, 22, 24, 26, 28, 30).
There is a continuous section break after this line.
This line is in the new section. Next here is an empty section.
This line is in the fourth section.
# <a name="_toc76372686"></a>**Paragraph Justify**
This is a justified paragraph with a single segment. 111111111111111111111111111111111111111111.
Also a justified **paragraph** reset to left because of multiple segments. 111111111111111111111111111111111111111111.
# **Non-English Characters**
Wingdings: (x, Symbol: WÄ
Russian: Теперь немного по русски.
# <a name="_toc76372687"></a>**Tables**
|Cell 1.1 Left|Cell 1.2 Right|||
| :- | -: | :- | :- |
|Cell 2.1 Centered vertically|Cell 2.2 with background|Cell 2.3 with line break<br>and coloured border.||
|Cell 3.1 Bottom vertically|<p>Cell 3.2</p><p>Centered</p><p>Horizontally</p>|Cell 3.3 No border||
|Left red, blue top, green right and yellow bottom.|
| :- |
|Table with left indent and merged cells.||||
| :- | :- | :- | :- |
|||||
|||||
**Cell padding etc.**
|<p>Cell padding.</p><p>Top: 0.1, bottom 0.2</p><p>Left: 0.5, Right 0.4</p>|Zero padding on all sides, right aligned.|
| :- | -: |
|Outer 1.1|Outer 1.2. There is a nested table here||
| :- | :-: | -: |
|**Nested 1.1**|**Nested 1.2**|
| :- | :- |
|||Outer 1.3|
| :- | :-: | -: |
#
# <a name="_toc76372688"></a>**Lists**
**Numbered list:**
1. Item 1
1. Item 2
1. Item 2.1
1. Item 2.2
1. Item 3
**Bulleted list:**
- Item 1
- Item 2
- Item 2.1
- Item 2.2
- Item 3
#
# <a name="_toc76372689"></a>**Images**
This section starts from a new page.
**Ellipse text**
There is an image in a black border in the top right corner, but it will drop down into the text. There is also a transparent ellipse with text that overlaps the picture.
Inline JPEG in a separate paragraph.

Inline GIF scaled 50% and WMF scaled 25% in a paragraph. This text is before the image and  this text is after the image.
Images in a table. Left and right aligned.
|||
| :- | -: |
Inline text box  is here and inline ellipse  is here.
New section that starts from a new page is here.
It has portrait orientation and margins.
# <a name="_toc76372690"></a>**Fields**
Merge field «FirstName»
Page number 5
Hyperlink [Aspose.com](http://www.aspose.com)
TOC
[Font Formatting 1](#_toc76372684)
[Paragraph Formatting 1](#_toc76372685)
[Non-English Characters 2](#_toc76372686)
[Tables 2](#_toc76372687)
[Lists 2](#_toc76372688)
[Images 4](#_toc76372689)
[Fields 5](#_toc76372690)
# **Form Fields**
Edit <a name="text1"></a>test text
Checkbox <a name="check1"></a>
Combobox <a name="dropdown1"></a>
# **Footnotes and Endnotes**
This line has a footnote at the end.[^1]
This line has an endnote at the end.[^2]
[^1]: Footnote 1.
[^2]: Endnote 1.
Riepilogo
GroupDocs.Markdown for .NET ti aiuta a convertire un’ampia gamma di formati di documento in Markdown semantico pronto per i sistemi LLM + RAG. Preserva la struttura e il significato del documento, funziona on‑premise e supporta i formati aziendali più comuni — rendendolo una scelta pratica per le organizzazioni che devono preparare grandi collezioni di documenti per il consumo da parte dell’IA.
Per saperne di più
- Home del prodotto: https://products.groupdocs.com/markdown/net/
- Documentazione: https://docs.groupdocs.com/markdown/net/
- Informazioni sulla licenza: https://about.groupdocs.com/legal/
- Download: https://releases.groupdocs.com/markdown/net/
Supporto e feedback
Per domande o assistenza tecnica, utilizza il nostro Forum di supporto gratuito — saremo felici di aiutarti.