
Maak uw bedrijfsdocumenten AI‑klaar — betrouwbaar, on‑premise en semantisch.
Het komt vaak voor dat organisaties hun documentatie opslaan in PDF-, DOCX-, XLSX- en ePub‑formaten. Terwijl LLM’s (large language models) goed werken met HTML of platte tekst, moeten deze native documentformaten eerst worden geconverteerd voordat ze effectief kunnen worden gebruikt in LLM + RAG‑pijplijnen waarbij we met een document of een set documenten willen chatten.
LLM (Large Language Model) — een voorgetraind AI‑model dat tekst genereert en antwoorden geeft op basis van grote tekstcorpora.
RAG (Retrieval‑Augmented Generation) — een aanpak die een LLM combineert met een externe kennisbank (bijvoorbeeld bedrijfsdocumenten) zodat het model domeinspecifieke inhoud kan ophalen en erover kan redeneren.
Het volgende sequentiediagram illustreert de typische stappen die betrokken zijn bij het genereren van een antwoord op een vraag:
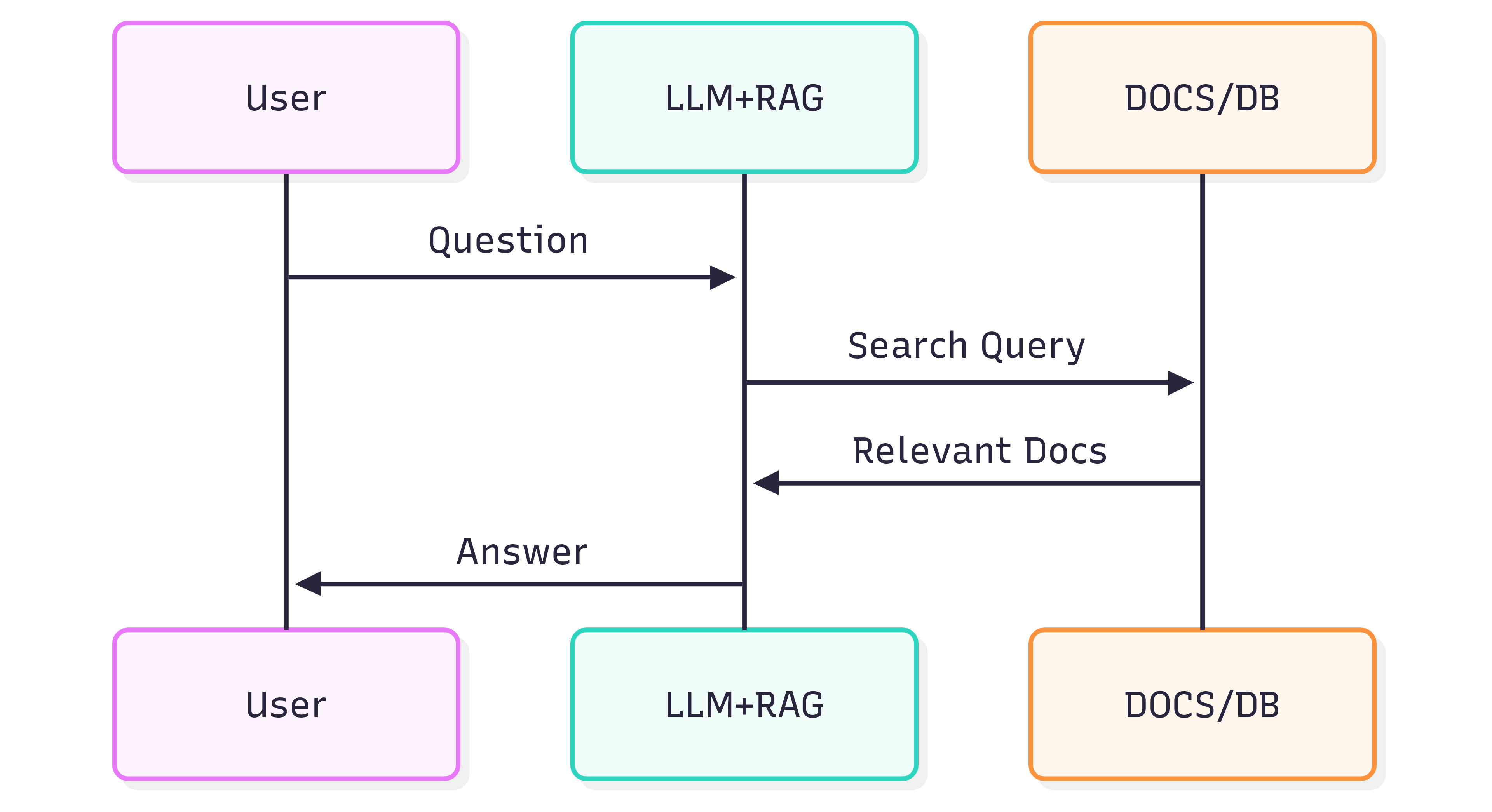
De kwaliteit van de antwoorden die u krijgt van een Systeem (LLM + RAG) hangt zowel af van het Systeem zelf als van hoe goed de bron‑documenten hun structuur en betekenis behouden wanneer ze in de retrieval‑pipeline worden gevoed.
Het probleem
Documentopmaak is niet alleen visueel — ze draagt semantiek. Koppen, lijsten, tabellen, vet/italic nadruk, bijschriften en inline‑afbeeldingen geven allemaal betekenis die een LLM helpt de context te begrijpen. Het naïef converteren van documenten (bijvoorbeeld met OCR die elke pagina als een platte afbeelding behandelt) verliest vaak die semantiek. Als gevolg daarvan kunnen RAG‑retrieval en downstream LLM‑antwoorden onnauwkeurig of ruisachtig worden.
OCR kan helpen bij gescande documenten, maar verwijdert vaak structuur (lijsten die over pagina’s heen lopen, tabelranden die verkeerd worden geïnterpreteerd, verloren annotaties). Het voegt bovendien kosten en infrastructuur‑overhead toe bij het verwerken van grote archieven.
De oplossing
Een alternatieve aanpak is om documenten te parseren met structureel bewustzijn en die structuur te exporteren naar een semantisch, LLM‑vriendelijk formaat — Markdown. Markdown is lichtgewicht, breed ondersteund en behoudt koppen, lijsten, tabellen, codeblokken, nadruk, bijschriften en afbeeldingsreferenties — precies de kenmerken die de kwaliteit van retrieval verbeteren.
GroupDocs.Markdown for .NET converteert populaire documentformaten (PDF, DOCX, XLSX, ePub en meer) naar schone, semantische Markdown die geschikt is voor ingestie in RAG‑systemen. Het is een on‑premise .NET‑bibliotheek, dus alle verwerking gebeurt binnen uw eigen omgeving — geen externe services, geen datalekken en geen afhankelijkheid van remote GPU’s.
Hoe u kunt beginnen
GroupDocs.Markdown for .NET is beschikbaar als een NuGet‑pakket, en ook als MSI‑ en ZIP‑downloads.
Installeer het NuGet‑pakket met de .NET‑CLI:
dotnet add package GroupDocs.Markdown
Of download installateurs en assemblies vanaf de officiële downloadpagina: https://releases.groupdocs.com/markdown/net/
Voorbeeldgebruik (voeg toe aan Program.cs):
// Import the namespace
using GroupDocs.Markdown;
// Set the license (optional for evaluation)
License.Set("GroupDocs.Markdown.lic");
// Instantiate the converter for a source document
var converter = new MarkdownConverter("rich-text-formatting.docx");
// Convert and save output to file
converter.Convert("rich-text-formatting.md");
Het geconverteerde rich-text-formatting.md‑bestand wordt opgeslagen in dezelfde map als uw applicatie.
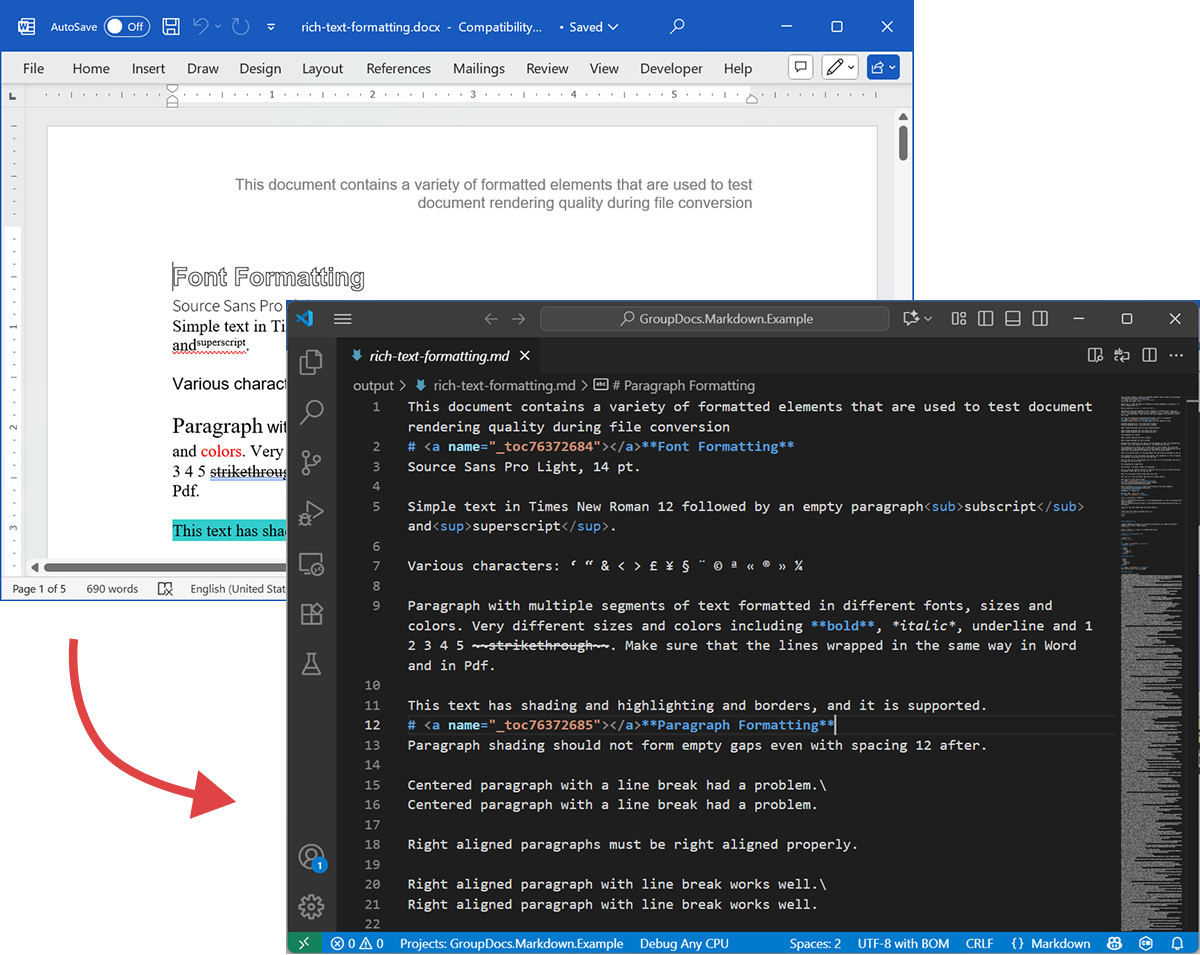
De volgende screenshot toont het invoer‑DOCX‑bestand en de gegenereerde Markdown.
Als u zonder licentie werkt, zal de evaluatiemodus een beperkt aantal pagina’s verwerken (bijvoorbeeld de eerste drie pagina’s). Om het volledige product te proberen, vraagt u een tijdelijke licentie aan.
Om een tijdelijke licentie aan te vragen, opent u de Purchase Wizard, vult u de contactgegevens in en klikt u op Get a temporary license in de stap Contact Details. De tijdelijke licentie wordt per e‑mail naar u verzonden.
Meer informatie over tijdelijke licenties: https://purchase.groupdocs.com/temporary-license/.
Ondersteunde bestandsformaten
GroupDocs.Markdown for .NET ondersteunt een brede reeks gangbare enterprise‑ en ebook‑formaten. De volledige lijst van ondersteunde extensies:
- PDF
pdf
- Spreadsheets
.xls,.xlsx,.xlsb,.xlsm,.xlt,.xltx,.xltm,.xlam,.csv,.tsv,.ods,.ots,.fods,.numbers,.sxc
- Word / Rich Text
.doc,.docx,.dot,.dotm,.dotx,.docm,.rtf,.odt,.ott
- Ebooks
.azw3,.mobi,.epub
- Text / Markup / Help
.chm,.xml,.txt
Hoe het werkt (internals — hoog niveau)
Wanneer een document wordt verwerkt, vinden twee hoofd‑fasen plaats:
-
Documentmodel‑extractie
Het document wordt geparseerd naar een in‑memory objectmodel dat structurele elementen (paragrafen, koppen, lijsten, tabellen, afbeeldingen, voetnoten, annotaties, enz.) vertegenwoordigt. De parser streeft ernaar de semantiek te behouden (bijvoorbeeld lijst‑nesting, tabelcellen en afbeeldingsbijschriften). -
Markdown‑generatie
Het objectmodel wordt doorlopen en omgezet naar Markdown volgens configureerbare conversie‑opties (hoe om te gaan met afbeeldingen, tabelopmaak, kopniveaus, speciale annotaties, enz.). Het resultaat is een leesbaar, semantisch betekenisvol Markdown‑bestand dat klaar is voor indexering door uw RAG‑pipeline.
Exportvoorbeeld
De code‑voorbeeld hierboven laat zien hoe u DOCX naar Markdown exporteert. Laten we dit code‑voorbeeld nemen en de bron‑ en uitvoerbestanden bekijken als demonstratie.
Bron DOCX
Het bronbestand rich-text-formatting.docx bevat diverse inhoudsblokken en is sterk opgemaakt om de belangrijkste semantische elementen te benadrukken.
Uitvoer Markdown
De uitvoerinhoud van rich-text-formatting.md wordt hieronder weergegeven, waarbij wordt getoond hoe verschillende opmaak‑elementen worden gerepresenteerd in het gegenereerde Markdown‑bestand.
This document contains a variety of formatted elements that are used to test document rendering quality during file conversion
# <a name="_toc76372684"></a>**Font Formatting**
Source Sans Pro Light, 14 pt.
Simple text in Times New Roman 12 followed by an empty paragraph<sub>subscript</sub> and<sup>superscript</sup>.
Various characters: ‘ “ & < > £ ¥ § ¨ © ª « ® » ¼
Paragraph with multiple segments of text formatted in different fonts, sizes and colors. Very different sizes and colors including **bold**, *italic*, underline and 1 2 3 4 5 ~~strikethrough~~. Make sure that the lines wrapped in the same way in Word and in Pdf.
This text has shading and highlighting and borders, and it is supported.
# <a name="_toc76372685"></a>**Paragraph Formatting**
Paragraph shading should not form empty gaps even with spacing 12 after.
Centered paragraph with a line break had a problem.\
Centered paragraph with a line break had a problem.
Right aligned paragraphs must be right aligned properly.
Right aligned paragraph with line break works well.\
Right aligned paragraph with line break works well.
This paragraph has a border.
Right aligned condensed text had a problem.
Right aligned expanded text had a problem.
Spacing after and before do not add up, just the greater is used. This paragraph has 12 after. Also, when indents are different, the shading does not join.
This paragraph has 12 before, but in total there is only 12 above. Also note that shading belongs to the paragraph at the top and shading of this paragraph does not go down unless next paragraph has shading too. There are 24 points below.
There are 24 points above, but the gap between this and previous paragraph is only 24.
This paragraph is a test for double line spacing. This paragraph is a test for double line spacing. It also have 0.5” for the first line.
This is a test for 1.5 line spacing. This is a test for 1.5 line spacing. Also has -0.5” indent for the first line.
This paragraph has a page break
and centered. It actually creates two paragraphs.
This is a test for Exactly 20 points of spacing. This is a test for Exactly 20 points of spacing. TTTTTT (20, 22, 24, 26, 28, 30).
There is a continuous section break after this line.
This line is in the new section. Next here is an empty section.
This line is in the fourth section.
# <a name="_toc76372686"></a>**Paragraph Justify**
This is a justified paragraph with a single segment. 111111111111111111111111111111111111111111.
Also a justified **paragraph** reset to left because of multiple segments. 111111111111111111111111111111111111111111.
# **Non-English Characters**
Wingdings: (x, Symbol: WÄ
Russian: Теперь немного по русски.
# <a name="_toc76372687"></a>**Tables**
|Cell 1.1 Left|Cell 1.2 Right|||
| :- | -: | :- | :- |
|Cell 2.1 Centered vertically|Cell 2.2 with background|Cell 2.3 with line break<br>and coloured border.||
|Cell 3.1 Bottom vertically|<p>Cell 3.2</p><p>Centered</p><p>Horizontally</p>|Cell 3.3 No border||
|Left red, blue top, green right and yellow bottom.|
| :- |
|Table with left indent and merged cells.||||
| :- | :- | :- | :- |
|||||
|||||
**Cell padding etc.**
|<p>Cell padding.</p><p>Top: 0.1, bottom 0.2</p><p>Left: 0.5, Right 0.4</p>|Zero padding on all sides, right aligned.|
| :- | -: |
|Outer 1.1|Outer 1.2. There is a nested table here||
| :- | :-: | -: |
|**Nested 1.1**|**Nested 1.2**|
| :- | :- |
|||Outer 1.3|
| :- | :-: | -: |
#
# <a name="_toc76372688"></a>**Lists**
**Numbered list:**
1. Item 1
1. Item 2
1. Item 2.1
1. Item 2.2
1. Item 3
**Bulleted list:**
- Item 1
- Item 2
- Item 2.1
- Item 2.2
- Item 3
#
# <a name="_toc76372689"></a>**Images**
This section starts from a new page.
**Ellipse text**
There is an image in a black border in the top right corner, but it will drop down into the text. There is also a transparent ellipse with text that overlaps the picture.
Inline JPEG in a separate paragraph.

Inline GIF scaled 50% and WMF scaled 25% in a paragraph. This text is before the image and  this text is after the image.
Images in a table. Left and right aligned.
|||
| :- | -: |
Inline text box  is here and inline ellipse  is here.
New section that starts from a new page is here.
It has portrait orientation and margins.
# <a name="_toc76372690"></a>**Fields**
Merge field «FirstName»
Page number 5
Hyperlink [Aspose.com](http://www.aspose.com)
TOC
[Font Formatting 1](#_toc76372684)
[Paragraph Formatting 1](#_toc76372685)
[Non-English Characters 2](#_toc76372686)
[Tables 2](#_toc76372687)
[Lists 2](#_toc76372688)
[Images 4](#_toc76372689)
[Fields 5](#_toc76372690)
# **Form Fields**
Edit <a name="text1"></a>test text
Checkbox <a name="check1"></a>
Combobox <a name="dropdown1"></a>
# **Footnotes and Endnotes**
This line has a footnote at the end.[^1]
This line has an endnote at the end.[^2]
[^1]: Footnote 1.
[^2]: Endnote 1.
Samenvatting
GroupDocs.Markdown for .NET helpt u een breed scala aan documentformaten te converteren naar semantische Markdown die klaar is voor LLM + RAG‑systemen. Het behoudt documentstructuur en betekenis, draait on‑premise en ondersteunt gangbare enterprise‑formaten — waardoor het een praktische keuze is voor organisaties die grote documentcollecties AI‑klaar moeten maken.
Meer informatie
- Producthome: https://products.groupdocs.com/markdown/net/
- Documentatie: https://docs.groupdocs.com/markdown/net/
- Licentie‑informatie: https://about.groupdocs.com/legal/
- Downloads: https://releases.groupdocs.com/markdown/net/
Ondersteuning & feedback
Voor vragen of technische assistentie kunt u ons Free Support Forum gebruiken — we helpen u graag.