
Torne seus documentos corporativos prontos para IA — de forma confiável, on‑premise e semântica.
É bastante comum que as organizações mantenham sua documentação nos formatos PDF, DOCX, XLSX e ePub. Enquanto LLMs (large language models) funcionam bem com HTML ou texto simples, esses formatos de documento nativos precisam de conversão antes de poderem ser usados efetivamente em pipelines LLM + RAG onde queremos conversar com um documento ou um conjunto de documentos.
LLM (Large Language Model) — um modelo de IA pré‑treinado que gera texto e respostas com base em grandes corpora de texto.
RAG (Retrieval‑Augmented Generation) — uma abordagem que combina um LLM com uma base de conhecimento externa (por exemplo, documentos corporativos) para que o modelo possa recuperar e raciocinar sobre o conteúdo do domínio.
O diagrama de sequência a seguir ilustra as etapas típicas envolvidas na geração de uma resposta a uma pergunta:
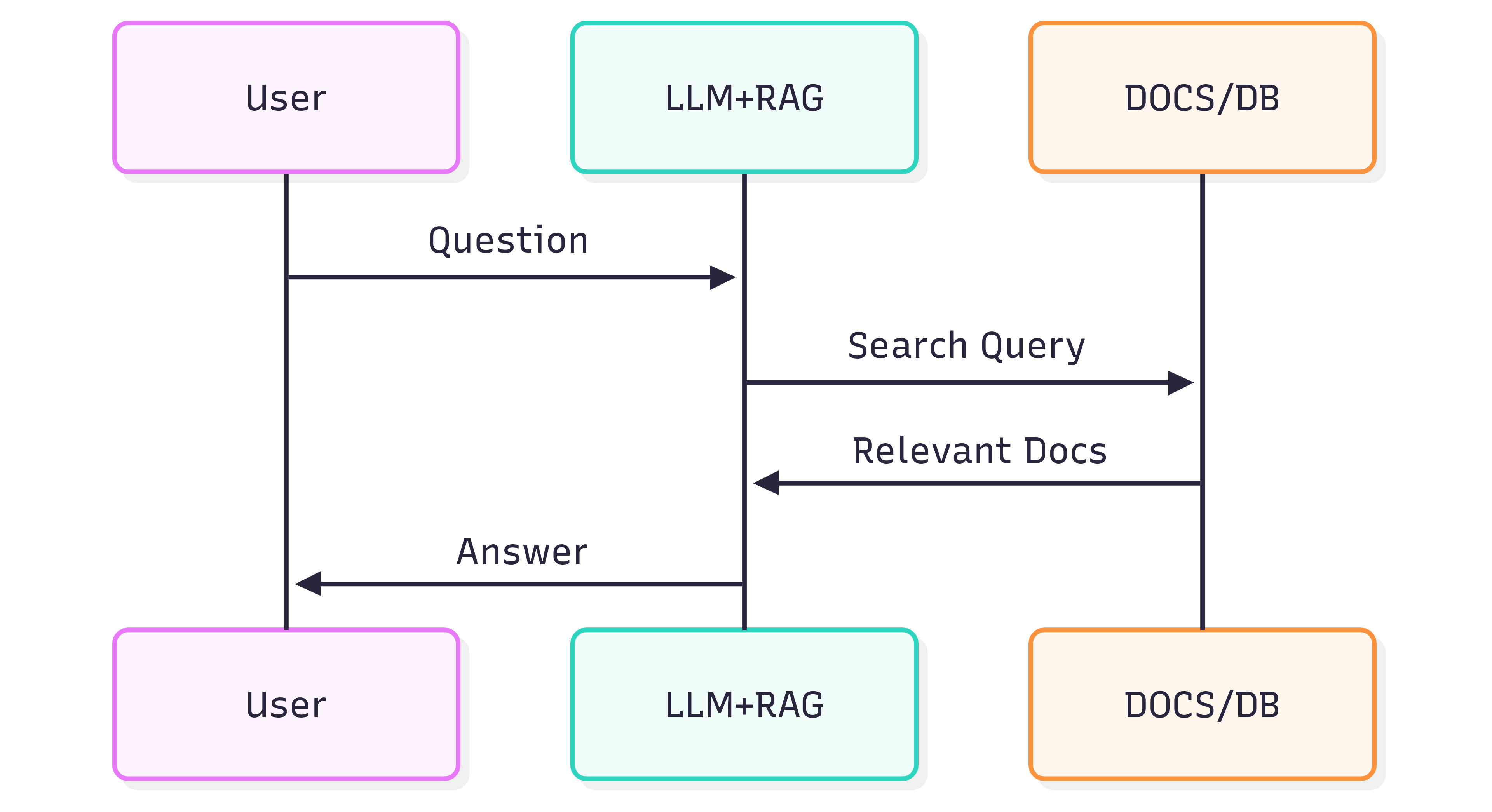
A qualidade das respostas que você obtém de um Sistema (LLM + RAG) depende tanto do próprio Sistema quanto de quão bem os documentos de origem preservam sua estrutura e significado quando alimentados na pipeline de recuperação.
O problema
A formatação de documentos não é apenas visual — ela carrega semântica. Títulos, listas, tabelas, ênfase em negrito/itálico, legendas e imagens embutidas transmitem significado que ajuda um LLM a entender o contexto. Converter documentos de forma ingênua (por exemplo, usando OCR que trata cada página como uma imagem plana) costuma perder essas semânticas. Como resultado, a recuperação RAG e as respostas subsequentes do LLM podem se tornar imprecisas ou ruidosas.
OCR pode ajudar para documentos escaneados, mas frequentemente remove a estrutura (listas divididas entre páginas, bordas de tabelas interpretadas erroneamente, anotações perdidas). Também adiciona custo e sobrecarga de infraestrutura ao processar grandes arquivos.
A solução
Uma abordagem alternativa é analisar documentos com consciência estrutural e exportar essa estrutura para um formato semântico e amigável ao LLM — Markdown. Markdown é leve, amplamente suportado e preserva títulos, listas, tabelas, blocos de código, ênfase, legendas e referências de imagens — exatamente os recursos que melhoram a qualidade da recuperação.
GroupDocs.Markdown for .NET converte formatos de documento populares (PDF, DOCX, XLSX, ePub e mais) em Markdown limpo e semântico, adequado para ingestão em sistemas RAG. É uma biblioteca .NET on‑premise, portanto todo o processamento ocorre dentro do seu ambiente — sem serviços externos, sem vazamento de dados e sem dependência de GPUs remotas.
Como começar
GroupDocs.Markdown for .NET está disponível como pacote NuGet, além de downloads MSI e ZIP.
Instale o pacote NuGet com a CLI do .NET:
dotnet add package GroupDocs.Markdown
Ou baixe instaladores e assemblies na página oficial de downloads: https://releases.groupdocs.com/markdown/net/
Exemplo de uso (adicione ao Program.cs):
// Import the namespace
using GroupDocs.Markdown;
// Set the license (optional for evaluation)
License.Set("GroupDocs.Markdown.lic");
// Instantiate the converter for a source document
var converter = new MarkdownConverter("rich-text-formatting.docx");
// Convert and save output to file
converter.Convert("rich-text-formatting.md");
O arquivo rich-text-formatting.md convertido será salvo na mesma pasta da sua aplicação.
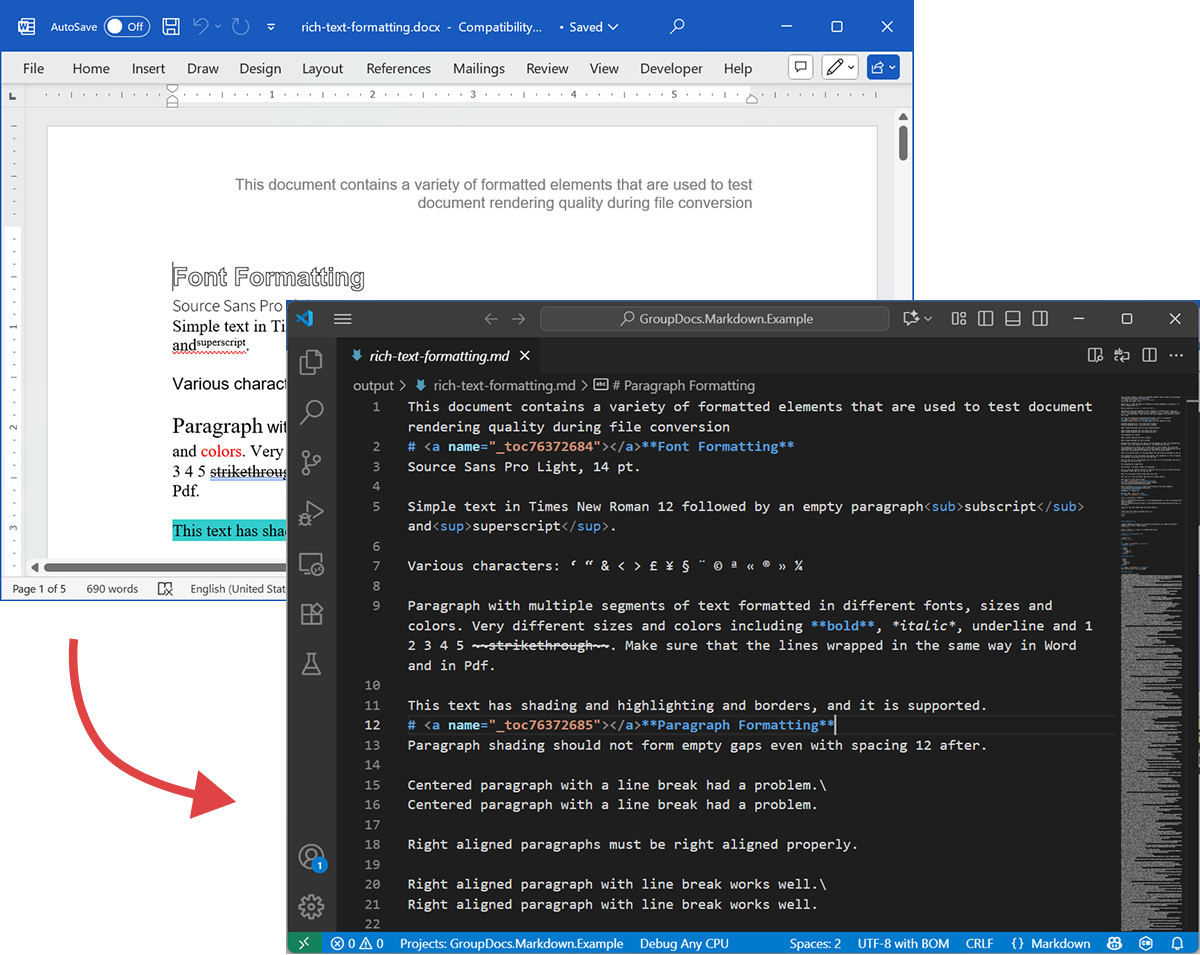
A captura de tela a seguir mostra o arquivo DOCX de entrada e o Markdown de saída.
Se você executar sem uma licença, o modo de avaliação processará um número limitado de páginas (por exemplo, as três primeiras). Para experimentar o produto completo, solicite uma licença temporária.
Para solicitar uma licença temporária, abra o Purchase Wizard, forneça os dados de contato e clique em Get a temporary license na etapa Contact Details. A licença temporária será enviada por e‑mail.
Saiba mais sobre licenças temporárias: https://purchase.groupdocs.com/temporary-license/.
Formatos de arquivo suportados
GroupDocs.Markdown for .NET suporta um amplo conjunto de formatos empresariais e de e‑book. A lista completa de extensões suportadas:
- PDF
pdf
- Planilhas
.xls,.xlsx,.xlsb,.xlsm,.xlt,.xltx,.xltm,.xlam,.csv,.tsv,.ods,.ots,.fods,.numbers,.sxc
- Word / Rich Text
.doc,.docx,.dot,.dotm,.dotx,.docm,.rtf,.odt,.ott
- Ebooks
.azw3,.mobi,.epub
- Texto / Marcação / Ajuda
.chm,.xml,.txt
Como funciona (internos — alto nível)
Quando um documento é processado, ocorrem duas fases principais:
-
Extração do modelo de documento
O documento é analisado em um modelo de objeto em memória que representa elementos estruturais (parágrafos, títulos, listas, tabelas, imagens, notas de rodapé, anotações etc.). O analisador se esforça para preservar a semântica (por exemplo, aninhamento de listas, células de tabela e legendas de imagens). -
Geração de Markdown
O modelo de objeto é percorrido e convertido para Markdown de acordo com opções de conversão configuráveis (como lidar com imagens, formatação de tabelas, níveis de títulos, anotações especiais etc.). O resultado é um arquivo Markdown legível e semanticamente significativo, pronto para indexação pela sua pipeline RAG.
Exemplo de exportação
O exemplo de código acima mostra como exportar DOCX para Markdown. Vamos usar esse exemplo de código e observar os arquivos de origem e de saída como demonstração.
DOCX de origem
O arquivo de origem rich-text-formatting.docx contém vários blocos de conteúdo e está fortemente formatado para destacar os principais elementos semânticos.
Markdown de saída
O conteúdo de saída de rich-text-formatting.md é apresentado abaixo, mostrando como diferentes elementos de formatação são representados no arquivo Markdown gerado.
This document contains a variety of formatted elements that are used to test document rendering quality during file conversion
# <a name="_toc76372684"></a>**Font Formatting**
Source Sans Pro Light, 14 pt.
Simple text in Times New Roman 12 followed by an empty paragraph<sub>subscript</sub> and<sup>superscript</sup>.
Various characters: ‘ “ & < > £ ¥ § ¨ © ª « ® » ¼
Paragraph with multiple segments of text formatted in different fonts, sizes and colors. Very different sizes and colors including **bold**, *italic*, underline and 1 2 3 4 5 ~~strikethrough~~. Make sure that the lines wrapped in the same way in Word and in Pdf.
This text has shading and highlighting and borders, and it is supported.
# <a name="_toc76372685"></a>**Paragraph Formatting**
Paragraph shading should not form empty gaps even with spacing 12 after.
Centered paragraph with a line break had a problem.\
Centered paragraph with a line break had a problem.
Right aligned paragraphs must be right aligned properly.
Right aligned paragraph with line break works well.\
Right aligned paragraph with line break works well.
This paragraph has a border.
Right aligned condensed text had a problem.
Right aligned expanded text had a problem.
Spacing after and before do not add up, just the greater is used. This paragraph has 12 after. Also, when indents are different, the shading does not join.
This paragraph has 12 before, but in total there is only 12 above. Also note that shading belongs to the paragraph at the top and shading of this paragraph does not go down unless next paragraph has shading too. There are 24 points below.
There are 24 points above, but the gap between this and previous paragraph is only 24.
This paragraph is a test for double line spacing. This paragraph is a test for double line spacing. It also have 0.5” for the first line.
This is a test for 1.5 line spacing. This is a test for 1.5 line spacing. Also has -0.5” indent for the first line.
This paragraph has a page break
and centered. It actually creates two paragraphs.
This is a test for Exactly 20 points of spacing. This is a test for Exactly 20 points of spacing. TTTTTT (20, 22, 24, 26, 28, 30).
There is a continuous section break after this line.
This line is in the new section. Next here is an empty section.
This line is in the fourth section.
# <a name="_toc76372686"></a>**Paragraph Justify**
This is a justified paragraph with a single segment. 111111111111111111111111111111111111111111.
Also a justified **paragraph** reset to left because of multiple segments. 111111111111111111111111111111111111111111.
# **Non-English Characters**
Wingdings: (x, Symbol: WÄ
Russian: Теперь немного по русски.
# <a name="_toc76372687"></a>**Tables**
|Cell 1.1 Left|Cell 1.2 Right|||
| :- | -: | :- | :- |
|Cell 2.1 Centered vertically|Cell 2.2 with background|Cell 2.3 with line break<br>and coloured border.||
|Cell 3.1 Bottom vertically|<p>Cell 3.2</p><p>Centered</p><p>Horizontally</p>|Cell 3.3 No border||
|Left red, blue top, green right and yellow bottom.|
| :- |
|Table with left indent and merged cells.||||
| :- | :- | :- | :- |
|||||
|||||
**Cell padding etc.**
|<p>Cell padding.</p><p>Top: 0.1, bottom 0.2</p><p>Left: 0.5, Right 0.4</p>|Zero padding on all sides, right aligned.|
| :- | -: |
|Outer 1.1|Outer 1.2. There is a nested table here||
| :- | :-: | -: |
|**Nested 1.1**|**Nested 1.2**|
| :- | :- |
|||Outer 1.3|
| :- | :-: | -: |
#
# <a name="_toc76372688"></a>**Lists**
**Numbered list:**
1. Item 1
1. Item 2
1. Item 2.1
1. Item 2.2
1. Item 3
**Bulleted list:**
- Item 1
- Item 2
- Item 2.1
- Item 2.2
- Item 3
#
# <a name="_toc76372689"></a>**Images**
This section starts from a new page.
**Ellipse text**
There is an image in a black border in the top right corner, but it will drop down into the text. There is also a transparent ellipse with text that overlaps the picture.
Inline JPEG in a separate paragraph.

Inline GIF scaled 50% and WMF scaled 25% in a paragraph. This text is before the image and  this text is after the image.
Images in a table. Left and right aligned.
|||
| :- | -: |
Inline text box  is here and inline ellipse  is here.
New section that starts from a new page is here.
It has portrait orientation and margins.
# <a name="_toc76372690"></a>**Fields**
Merge field «FirstName»
Page number 5
Hyperlink [Aspose.com](http://www.aspose.com)
TOC
[Font Formatting 1](#_toc76372684)
[Paragraph Formatting 1](#_toc76372685)
[Non-English Characters 2](#_toc76372686)
[Tables 2](#_toc76372687)
[Lists 2](#_toc76372688)
[Images 4](#_toc76372689)
[Fields 5](#_toc76372690)
# **Form Fields**
Edit <a name="text1"></a>test text
Checkbox <a name="check1"></a>
Combobox <a name="dropdown1"></a>
# **Footnotes and Endnotes**
This line has a footnote at the end.[^1]
This line has an endnote at the end.[^2]
[^1]: Footnote 1.
[^2]: Endnote 1.
Resumo
GroupDocs.Markdown for .NET ajuda você a converter uma ampla gama de formatos de documento em Markdown semântico, pronto para sistemas LLM + RAG. Ele preserva a estrutura e o significado do documento, funciona on‑premise e suporta formatos empresariais comuns — tornando‑se uma escolha prática para organizações que precisam preparar grandes coleções de documentos para consumo por IA.
Saiba mais
- Página do produto: https://products.groupdocs.com/markdown/net/
- Documentação: https://docs.groupdocs.com/markdown/net/
- Informações de licença: https://about.groupdocs.com/legal/
- Downloads: https://releases.groupdocs.com/markdown/net/
Suporte e feedback
Para dúvidas ou assistência técnica, use nosso Free Support Forum — teremos prazer em ajudar.