
Сделайте ваши корпоративные документы готовыми к ИИ — надёжно, локально и семантически.
Довольно часто организации хранят свою документацию в форматах PDF, DOCX, XLSX и ePub. В то время как LLM (large language models) хорошо работают с HTML или простым текстом, эти родные форматы документов требуют конвертации, прежде чем их можно будет эффективно использовать в конвейерах LLM + RAG, где мы хотим вести диалог с документом или набором документов.
LLM (Large Language Model) — предварительно обученная AI‑модель, генерирующая текст и ответы на основе больших корпусов текста.
RAG (Retrieval‑Augmented Generation) — подход, объединяющий LLM с внешней базой знаний (например, корпоративными документами), чтобы модель могла извлекать и рассуждать над содержимым домена.
Следующая диаграмма последовательности иллюстрирует типичные шаги, участвующие в генерации ответа на вопрос:
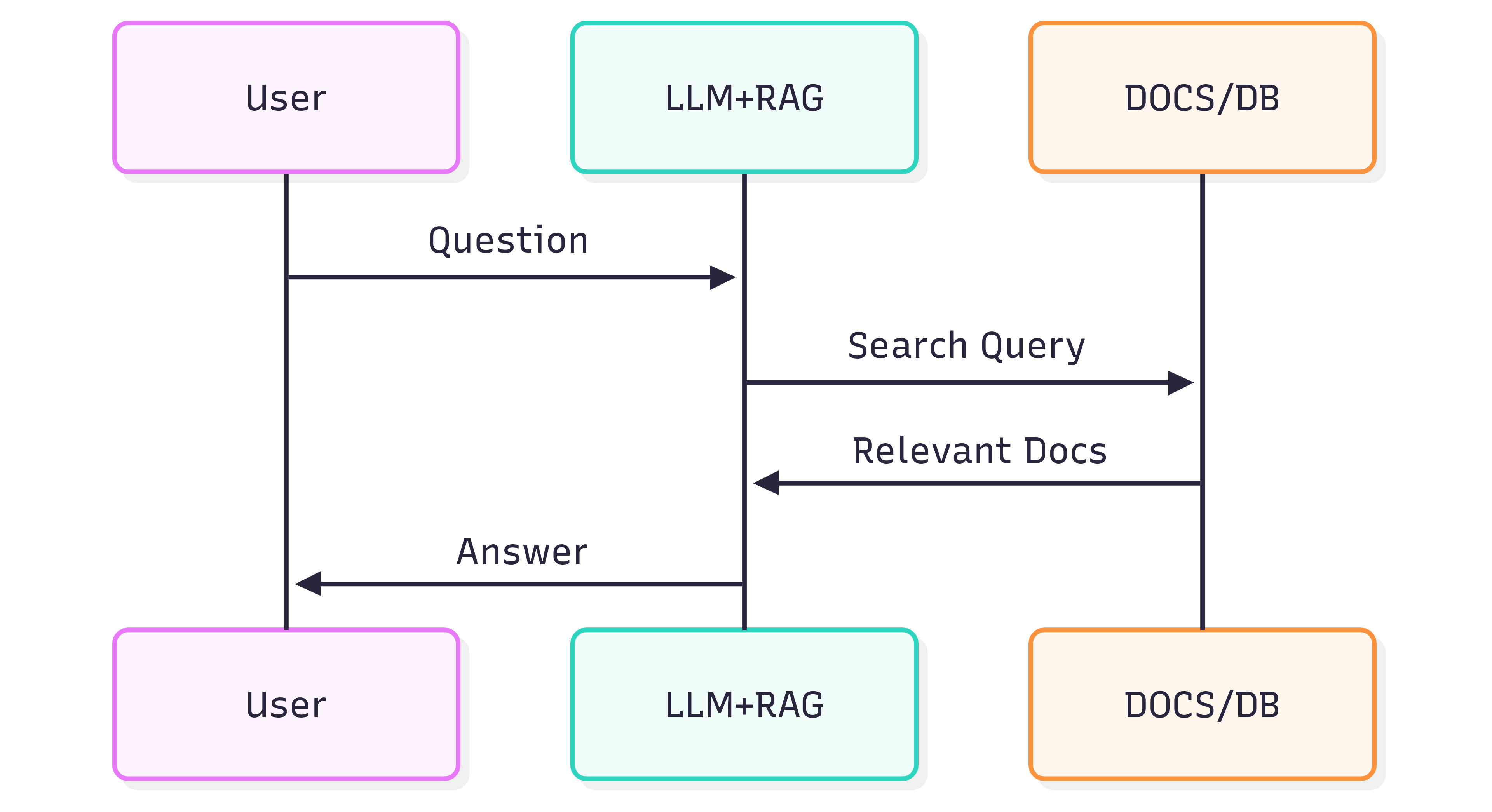
Качество ответов, получаемых от Системы (LLM + RAG), зависит как от самой Системы, так и от того, насколько хорошо исходные документы сохраняют свою структуру и смысл при передаче в конвейер извлечения.
Проблема
Форматирование документа — это не только визуальное оформление, но и семантика. Заголовки, списки, таблицы, выделения жирным/курсивом, подписи и встроенные изображения передают смысл, который помогает LLM понять контекст. Наивная конвертация документов (например, с помощью OCR, который рассматривает каждую страницу как плоское изображение) часто теряет эту семантику. В результате извлечение в RAG и последующие ответы LLM могут стать неточными или шумными.
OCR может помочь для отсканированных документов, но часто удаляет структуру (списки, разбитые по страницам, границы таблиц, неверно интерпретированные, потерянные аннотации). Кроме того, он добавляет затраты и нагрузку на инфраструктуру при обработке больших архивов.
Решение
Альтернативный подход — парсить документы с учётом их структуры и экспортировать эту структуру в семантический, удобный для LLM формат — Markdown. Markdown лёгок, широко поддерживается и сохраняет заголовки, списки, таблицы, блоки кода, выделения, подписи и ссылки на изображения — именно те функции, которые повышают качество извлечения.
GroupDocs.Markdown for .NET преобразует популярные форматы документов (PDF, DOCX, XLSX, ePub и другие) в чистый, семантический Markdown, пригодный для загрузки в RAG‑системы. Это локальная .NET‑библиотека, поэтому вся обработка происходит внутри вашего окружения — без внешних сервисов, утечки данных и зависимости от удалённых GPU.
Как начать
GroupDocs.Markdown for .NET доступен как пакет NuGet, а также в виде MSI и ZIP‑загрузок.
Установите пакет NuGet с помощью .NET CLI:
dotnet add package GroupDocs.Markdown
Или скачайте установщики и сборки со страницы официальных загрузок: https://releases.groupdocs.com/markdown/net/
Пример использования (добавьте в Program.cs):
// Import the namespace
using GroupDocs.Markdown;
// Set the license (optional for evaluation)
License.Set("GroupDocs.Markdown.lic");
// Instantiate the converter for a source document
var converter = new MarkdownConverter("rich-text-formatting.docx");
// Convert and save output to file
converter.Convert("rich-text-formatting.md");
Преобразованный файл rich-text-formatting.md будет сохранён в той же папке, что и ваше приложение.
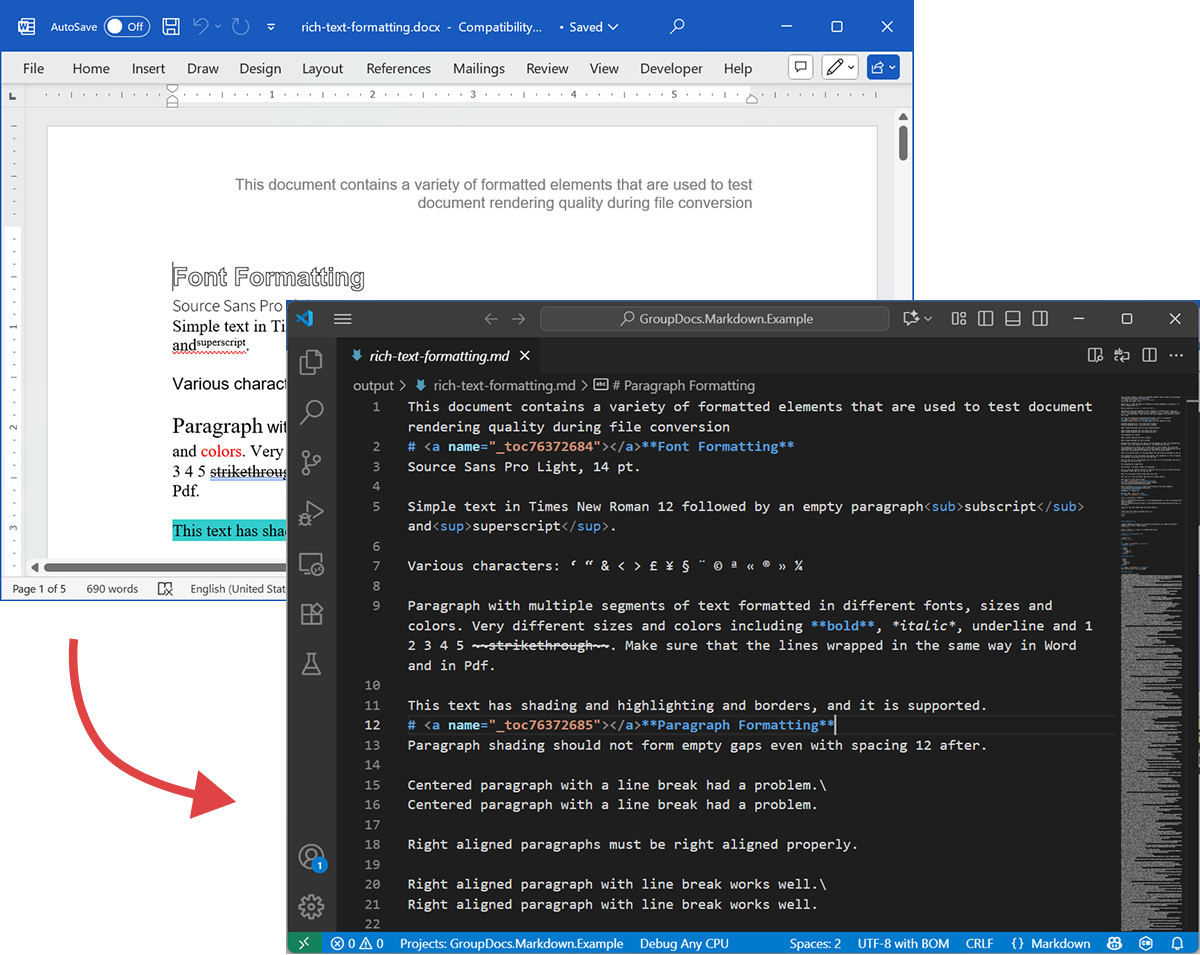
На следующем скриншоте показан входной DOCX‑файл и полученный Markdown.
Если запускать без лицензии, режим оценки обработает ограниченное количество страниц (например, первые три страницы). Чтобы попробовать полную версию продукта, запросите временную лицензию.
Чтобы запросить временную лицензию, откройте Purchase Wizard, укажите контактные данные и нажмите Get a temporary license на шаге Contact Details. Временная лицензия будет отправлена вам по электронной почте.
Подробнее о временных лицензиях: https://purchase.groupdocs.com/temporary-license/.
Поддерживаемые форматы файлов
GroupDocs.Markdown for .NET поддерживает широкий набор распространённых корпоративных и электронных форматов. Полный список поддерживаемых расширений:
- PDF
pdf
- Электронные таблицы
.xls,.xlsx,.xlsb,.xlsm,.xlt,.xltx,.xltm,.xlam,.csv,.tsv,.ods,.ots,.fods,.numbers,.sxc
- Word / Rich Text
.doc,.docx,.dot,.dotm,.dotx,.docm,.rtf,.odt,.ott
- Электронные книги
.azw3,.mobi,.epub
- Текст / Разметка / Справка
.chm,.xml,.txt
Как это работает (внутренности — высокий уровень)
При обработке документа происходит две основных фазы:
-
Извлечение модели документа
Документ парсится в объектную модель в памяти, представляющую структурные элементы (абзацы, заголовки, списки, таблицы, изображения, сноски, аннотации и т.д.). Парсер стремится сохранить семантику (например, вложенность списков, ячейки таблиц и подписи к изображениям). -
Генерация Markdown
Объектная модель обходится и преобразуется в Markdown согласно настраиваемым параметрам конвертации (как обрабатывать изображения, форматирование таблиц, уровни заголовков, специальные аннотации и т.д.). В результате получается читаемый, семантически значимый файл Markdown, готовый к индексации вашим конвейером RAG.
Пример экспорта
Приведённый выше пример кода показывает, как экспортировать DOCX в Markdown. Возьмём этот пример и посмотрим на исходный и результирующий файлы в качестве демонстрации.
Исходный DOCX
Исходный файл rich-text-formatting.docx содержит различные блоки контента и сильно отформатирован, чтобы подчеркнуть основные семантические элементы.
Полученный Markdown
Содержимое rich-text-formatting.md приведено ниже, показывая, как разные элементы форматирования представлены в сгенерированном файле Markdown.
This document contains a variety of formatted elements that are used to test document rendering quality during file conversion
# <a name="_toc76372684"></a>**Font Formatting**
Source Sans Pro Light, 14 pt.
Simple text in Times New Roman 12 followed by an empty paragraph<sub>subscript</sub> and<sup>superscript</sup>.
Various characters: ‘ “ & < > £ ¥ § ¨ © ª « ® » ¼
Paragraph with multiple segments of text formatted in different fonts, sizes and colors. Very different sizes and colors including **bold**, *italic*, underline and 1 2 3 4 5 ~~strikethrough~~. Make sure that the lines wrapped in the same way in Word and in Pdf.
This text has shading and highlighting and borders, and it is supported.
# <a name="_toc76372685"></a>**Paragraph Formatting**
Paragraph shading should not form empty gaps even with spacing 12 after.
Centered paragraph with a line break had a problem.\
Centered paragraph with a line break had a problem.
Right aligned paragraphs must be right aligned properly.
Right aligned paragraph with line break works well.\
Right aligned paragraph with line break works well.
This paragraph has a border.
Right aligned condensed text had a problem.
Right aligned expanded text had a problem.
Spacing after and before do not add up, just the greater is used. This paragraph has 12 after. Also, when indents are different, the shading does not join.
This paragraph has 12 before, but in total there is only 12 above. Also note that shading belongs to the paragraph at the top and shading of this paragraph does not go down unless next paragraph has shading too. There are 24 points below.
There are 24 points above, but the gap between this and previous paragraph is only 24.
This paragraph is a test for double line spacing. This paragraph is a test for double line spacing. It also have 0.5” for the first line.
This is a test for 1.5 line spacing. This is a test for 1.5 line spacing. Also has -0.5” indent for the first line.
This paragraph has a page break
and centered. It actually creates two paragraphs.
This is a test for Exactly 20 points of spacing. This is a test for Exactly 20 points of spacing. TTTTTT (20, 22, 24, 26, 28, 30).
There is a continuous section break after this line.
This line is in the new section. Next here is an empty section.
This line is in the fourth section.
# <a name="_toc76372686"></a>**Paragraph Justify**
This is a justified paragraph with a single segment. 111111111111111111111111111111111111111111.
Also a justified **paragraph** reset to left because of multiple segments. 111111111111111111111111111111111111111111.
# **Non-English Characters**
Wingdings: (x, Symbol: WÄ
Russian: Теперь немного по русски.
# <a name="_toc76372687"></a>**Tables**
|Cell 1.1 Left|Cell 1.2 Right|||
| :- | -: | :- | :- |
|Cell 2.1 Centered vertically|Cell 2.2 with background|Cell 2.3 with line break<br>and coloured border.||
|Cell 3.1 Bottom vertically|<p>Cell 3.2</p><p>Centered</p><p>Horizontally</p>|Cell 3.3 No border||
|Left red, blue top, green right and yellow bottom.|
| :- |
|Table with left indent and merged cells.||||
| :- | :- | :- | :- |
|||||
|||||
**Cell padding etc.**
|<p>Cell padding.</p><p>Top: 0.1, bottom 0.2</p><p>Left: 0.5, Right 0.4</p>|Zero padding on all sides, right aligned.|
| :- | -: |
|Outer 1.1|Outer 1.2. There is a nested table here||
| :- | :-: | -: |
|**Nested 1.1**|**Nested 1.2**|
| :- | :- |
|||Outer 1.3|
| :- | :-: | -: |
#
# <a name="_toc76372688"></a>**Lists**
**Numbered list:**
1. Item 1
1. Item 2
1. Item 2.1
1. Item 2.2
1. Item 3
**Bulleted list:**
- Item 1
- Item 2
- Item 2.1
- Item 2.2
- Item 3
#
# <a name="_toc76372689"></a>**Images**
This section starts from a new page.
**Ellipse text**
There is an image in a black border in the top right corner, but it will drop down into the text. There is also a transparent ellipse with text that overlaps the picture.
Inline JPEG in a separate paragraph.

Inline GIF scaled 50% and WMF scaled 25% in a paragraph. This text is before the image and  this text is after the image.
Images in a table. Left and right aligned.
|||
| :- | -: |
Inline text box  is here and inline ellipse  is here.
New section that starts from a new page is here.
It has portrait orientation and margins.
# <a name="_toc76372690"></a>**Fields**
Merge field «FirstName»
Page number 5
Hyperlink [Aspose.com](http://www.aspose.com)
TOC
[Font Formatting 1](#_toc76372684)
[Paragraph Formatting 1](#_toc76372685)
[Non-English Characters 2](#_toc76372686)
[Tables 2](#_toc76372687)
[Lists 2](#_toc76372688)
[Images 4](#_toc76372689)
[Fields 5](#_toc76372690)
# **Form Fields**
Edit <a name="text1"></a>test text
Checkbox <a name="check1"></a>
Combobox <a name="dropdown1"></a>
# **Footnotes and Endnotes**
This line has a footnote at the end.[^1]
This line has an endnote at the end.[^2]
[^1]: Footnote 1.
[^2]: Endnote 1.
Итоги
GroupDocs.Markdown for .NET помогает конвертировать широкий спектр форматов документов в семантический Markdown, готовый для систем LLM + RAG. Он сохраняет структуру и смысл документа, работает локально и поддерживает распространённые корпоративные форматы — что делает его практичным выбором для организаций, которым необходимо подготовить большие коллекции документов к потреблению ИИ.
Узнать больше
- Главная страница продукта: https://products.groupdocs.com/markdown/net/
- Документация: https://docs.groupdocs.com/markdown/net/
- Информация о лицензиях: https://about.groupdocs.com/legal/
- Загрузки: https://releases.groupdocs.com/markdown/net/
Поддержка и обратная связь
Для вопросов или технической помощи используйте наш Free Support Forum — будем рады помочь.