
Kurumsal belgelerinizi AI’ye hazır hâle getirin — güvenilir, yerinde ve anlamsal olarak.
Kuruluşların belgelerini PDF, DOCX, XLSX ve ePub formatlarında tutması oldukça yaygın bir durumdur. LLM’ler (büyük dil modelleri) HTML veya düz metinle iyi çalışırken, bu yerel belge formatlarının, bir belge ya da belge setiyle sohbet etmek istediğimiz LLM + RAG boru hatlarında etkili bir şekilde kullanılabilmesi için dönüştürülmesi gerekir.
LLM (Large Language Model) — büyük metin derlemelerine dayalı olarak metin ve yanıt üreten önceden eğitilmiş bir AI modelidir.
RAG (Retrieval-Augmented Generation) — bir LLM’yi harici bir bilgi tabanı (örneğin, kurumsal belgeler) ile birleştiren bir yaklaşımdır; böylece model alan içeriğini alabilir ve üzerinde akıl yürütebilir.
Aşağıdaki sıralama diyagramı, bir soruya yanıt üretirken tipik olarak izlenen adımları gösterir:
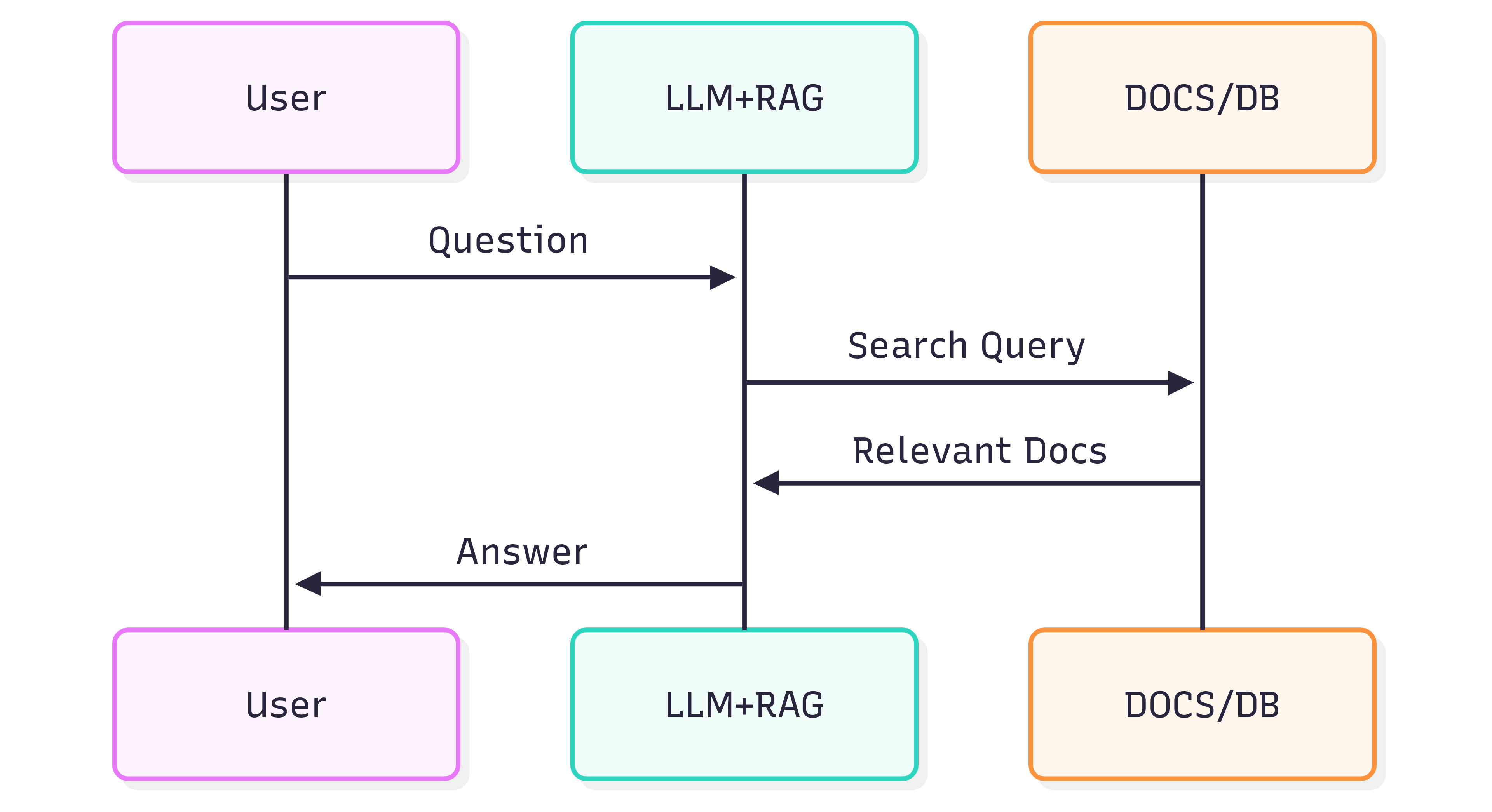
Bir Sistem (LLM + RAG) tarafından alınan yanıtların kalitesi, hem sistemin kendisine hem de kaynak belgelerin yapılarını ve anlamlarını alma sürecine ne kadar iyi koruduğuna bağlıdır.
Sorun
Belge biçimlendirmesi yalnızca görsel değildir — aynı zamanda anlamsal bilgi taşır. Başlıklar, listeler, tablolar, kalın/eğik vurgular, alt yazılar ve satır içi görseller, bir LLM’nin bağlamı anlamasına yardımcı olan anlamı iletir. Belgeleri (örneğin, her sayfayı düz bir görüntü olarak ele alan OCR kullanarak) basitçe dönüştürmek, bu anlamları sık sık kaybeder. Sonuç olarak, RAG alımı ve sonraki LLM yanıtları hatalı veya gürültülü olabilir.
OCR, taranmış belgeler için yardımcı olabilir ancak genellikle yapıyı kaldırır (sayfalar arasında bölünmüş listeler, yanlış yorumlanan tablo kenarlıkları, kaybolan açıklamalar). Ayrıca büyük arşivleri işlerken maliyet ve altyapı yükü ekler.
Çözüm
Alternatif bir yaklaşım, belgeleri yapısal farkındalıkla ayrıştırmak ve bu yapıyı anlamsal, LLM‑dostu bir formata — Markdown’a — dışa aktarmaktır. Markdown hafif, geniş çapta desteklenen ve başlıklar, listeler, tablolar, kod blokları, vurgular, alt yazılar ve görsel referansları korur — tam da alım kalitesini artıran özellikler.
GroupDocs.Markdown for .NET popüler belge formatlarını (PDF, DOCX, XLSX, ePub ve daha fazlasını) RAG sistemlerine beslenebilecek temiz, anlamsal Markdown’a dönüştürür. Bu, yerinde çalışan bir .NET kütüphanesidir; tüm işleme ortamınız içinde gerçekleşir — dış hizmet yok, veri sızıntısı yok ve uzak GPU bağımlılığı yok.
Başlarken
GroupDocs.Markdown for .NET bir NuGet paketi olarak ve ayrıca MSI ve ZIP indirmeleri şeklinde sunulmaktadır.
NuGet paketini .NET CLI ile kurun:
dotnet add package GroupDocs.Markdown
Veya resmi indirme sayfasından kurulum dosyalarını ve derlemeleri indirin: https://releases.groupdocs.com/markdown/net/
Örnek kullanım (Program.cs dosyasına ekleyin):
// Import the namespace
using GroupDocs.Markdown;
// Set the license (optional for evaluation)
License.Set("GroupDocs.Markdown.lic");
// Instantiate the converter for a source document
var converter = new MarkdownConverter("rich-text-formatting.docx");
// Convert and save output to file
converter.Convert("rich-text-formatting.md");
Dönüştürülen rich-text-formatting.md dosyası, uygulamanızın bulunduğu klasöre kaydedilecektir.
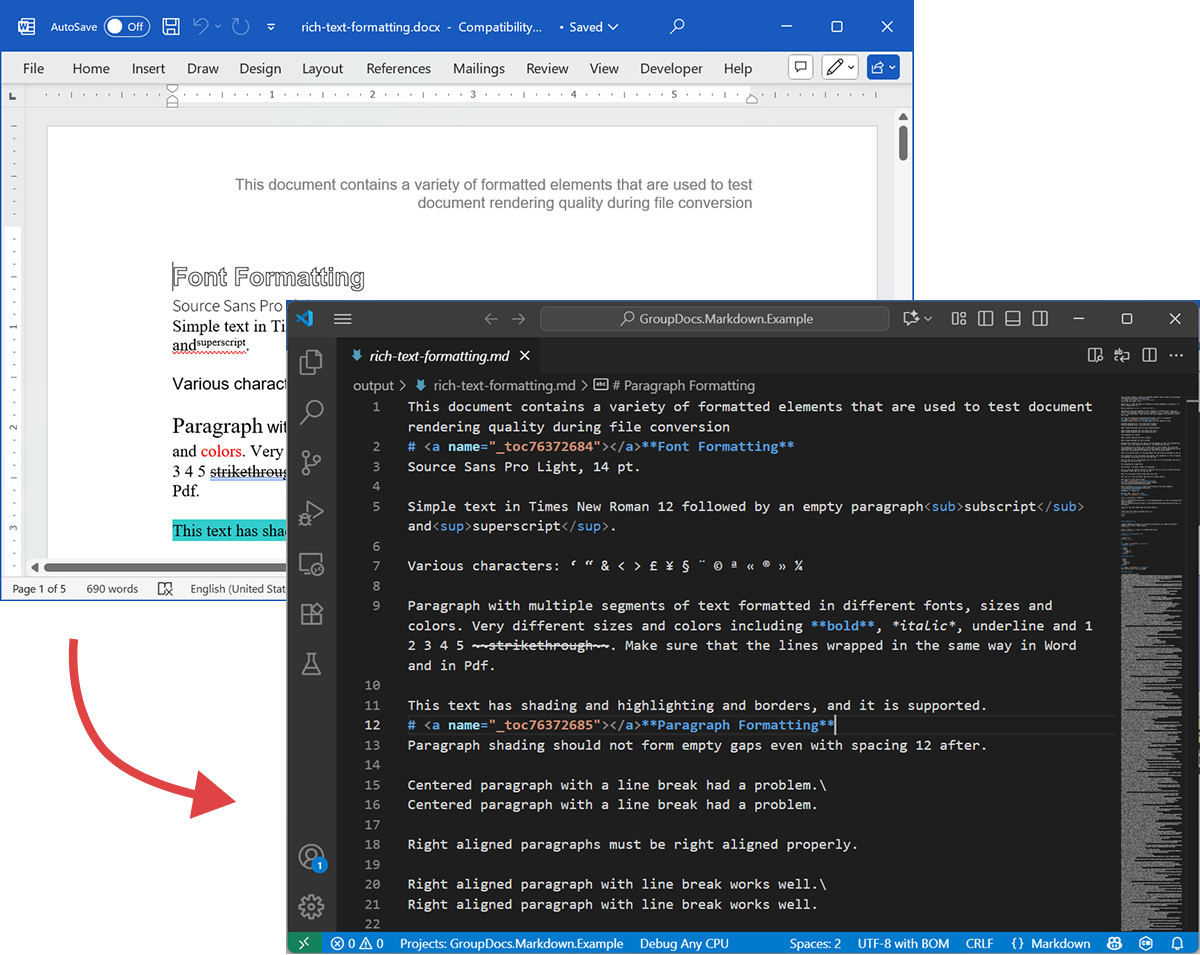
Aşağıdaki ekran görüntüsü, giriş DOCX dosyasını ve çıktı Markdown dosyasını gösterir.
Lisans olmadan çalıştırırsanız, değerlendirme modu sınırlı sayıda sayfayı işler (örneğin, ilk üç sayfa). Tam ürünü denemek için geçici bir lisans isteyin.
Geçici lisans talep etmek için Purchase Wizard sayfasını açın, iletişim bilgilerinizi girin ve Contact Details adımında Get a temporary license düğmesine tıklayın. Geçici lisans size e‑posta ile gönderilecektir.
Geçici lisanslar hakkında daha fazla bilgi: https://purchase.groupdocs.com/temporary-license/.
Desteklenen dosya formatları
GroupDocs.Markdown for .NET geniş bir kurumsal ve e‑kitap formatı yelpazesini destekler. Desteklenen uzantıların tam listesi:
- PDF
pdf
- Elektronik Tablo
.xls,.xlsx,.xlsb,.xlsm,.xlt,.xltx,.xltm,.xlam,.csv,.tsv,.ods,.ots,.fods,.numbers,.sxc
- Word / Zengin Metin
.doc,.docx,.dot,.dotm,.dotx,.docm,.rtf,.odt,.ott
- E‑kitaplar
.azw3,.mobi,.epub
- Metin / İşaretleme / Yardım
.chm,.xml,.txt
Nasıl çalışır (iç detaylar — yüksek seviye)
Bir belge işlendiğinde iki ana aşama gerçekleşir:
-
Belge modeli çıkarımı
Belge, yapısal öğeleri (paragraflar, başlıklar, listeler, tablolar, görseller, dipnotlar, açıklamalar vb.) temsil eden bellek içi bir nesne modeline ayrıştırılır. Ayrıştırıcı, anlamı korumaya çalışır (örneğin, liste iç içeliği, tablo hücreleri ve görsel alt yazıları). -
Markdown üretimi
Nesne modeli dolaşılır ve yapılandırılabilir dönüşüm seçeneklerine göre (görsellerin işlenmesi, tablo biçimlendirmesi, başlık seviyeleri, özel açıklamalar vb.) Markdown’a dönüştürülür. Sonuç, RAG boru hattınız tarafından indekslenmeye hazır, okunabilir ve anlamsal olarak anlamlı bir Markdown dosyasıdır.
Dışa Aktarım Örneği
Yukarıdaki kod örneği, DOCX’i Markdown’a dışa aktarmayı gösterir. Bu kod örneğini alıp kaynak ve çıktı dosyalarına bir göz atalım.
Kaynak DOCX
Kaynak dosya rich-text-formatting.docx çeşitli içerik blokları içerir ve ana anlamsal öğeleri vurgulamak için yoğun biçimlendirilmiştir.
Çıktı Markdown
rich-text-formatting.md dosyasının çıktısı aşağıda verilmiştir; farklı biçimlendirme öğelerinin oluşturulan Markdown dosyasında nasıl temsil edildiğini gösterir.
This document contains a variety of formatted elements that are used to test document rendering quality during file conversion
# <a name="_toc76372684"></a>**Font Formatting**
Source Sans Pro Light, 14 pt.
Simple text in Times New Roman 12 followed by an empty paragraph<sub>subscript</sub> and<sup>superscript</sup>.
Various characters: ‘ “ & < > £ ¥ § ¨ © ª « ® » ¼
Paragraph with multiple segments of text formatted in different fonts, sizes and colors. Very different sizes and colors including **bold**, *italic*, underline and 1 2 3 4 5 ~~strikethrough~~. Make sure that the lines wrapped in the same way in Word and in Pdf.
This text has shading and highlighting and borders, and it is supported.
# <a name="_toc76372685"></a>**Paragraph Formatting**
Paragraph shading should not form empty gaps even with spacing 12 after.
Centered paragraph with a line break had a problem.\
Centered paragraph with a line break had a problem.
Right aligned paragraphs must be right aligned properly.
Right aligned paragraph with line break works well.\
Right aligned paragraph with line break works well.
This paragraph has a border.
Right aligned condensed text had a problem.
Right aligned expanded text had a problem.
Spacing after and before do not add up, just the greater is used. This paragraph has 12 after. Also, when indents are different, the shading does not join.
This paragraph has 12 before, but in total there is only 12 above. Also note that shading belongs to the paragraph at the top and shading of this paragraph does not go down unless next paragraph has shading too. There are 24 points below.
There are 24 points above, but the gap between this and previous paragraph is only 24.
This paragraph is a test for double line spacing. This paragraph is a test for double line spacing. It also have 0.5” for the first line.
This is a test for 1.5 line spacing. This is a test for 1.5 line spacing. Also has -0.5” indent for the first line.
This paragraph has a page break
and centered. It actually creates two paragraphs.
This is a test for Exactly 20 points of spacing. This is a test for Exactly 20 points of spacing. TTTTTT (20, 22, 24, 26, 28, 30).
There is a continuous section break after this line.
This line is in the new section. Next here is an empty section.
This line is in the fourth section.
# <a name="_toc76372686"></a>**Paragraph Justify**
This is a justified paragraph with a single segment. 111111111111111111111111111111111111111111.
Also a justified **paragraph** reset to left because of multiple segments. 111111111111111111111111111111111111111111.
# **Non-English Characters**
Wingdings: (x, Symbol: WÄ
Russian: Теперь немного по русски.
# <a name="_toc76372687"></a>**Tables**
|Cell 1.1 Left|Cell 1.2 Right|||
| :- | -: | :- | :- |
|Cell 2.1 Centered vertically|Cell 2.2 with background|Cell 2.3 with line break<br>and coloured border.||
|Cell 3.1 Bottom vertically|<p>Cell 3.2</p><p>Centered</p><p>Horizontally</p>|Cell 3.3 No border||
|Left red, blue top, green right and yellow bottom.|
| :- |
|Table with left indent and merged cells.||||
| :- | :- | :- | :- |
|||||
|||||
**Cell padding etc.**
|<p>Cell padding.</p><p>Top: 0.1, bottom 0.2</p><p>Left: 0.5, Right 0.4</p>|Zero padding on all sides, right aligned.|
| :- | -: |
|Outer 1.1|Outer 1.2. There is a nested table here||
| :- | :-: | -: |
|**Nested 1.1**|**Nested 1.2**|
| :- | :- |
|||Outer 1.3|
| :- | :-: | -: |
#
# <a name="_toc76372688"></a>**Lists**
**Numbered list:**
1. Item 1
1. Item 2
1. Item 2.1
1. Item 2.2
1. Item 3
**Bulleted list:**
- Item 1
- Item 2
- Item 2.1
- Item 2.2
- Item 3
#
# <a name="_toc76372689"></a>**Images**
This section starts from a new page.
**Ellipse text**
There is an image in a black border in the top right corner, but it will drop down into the text. There is also a transparent ellipse with text that overlaps the picture.
Inline JPEG in a separate paragraph.

Inline GIF scaled 50% and WMF scaled 25% in a paragraph. This text is before the image and  this text is after the image.
Images in a table. Left and right aligned.
|||
| :- | -: |
Inline text box  is here and inline ellipse  is here.
New section that starts from a new page is here.
It has portrait orientation and margins.
# <a name="_toc76372690"></a>**Fields**
Merge field «FirstName»
Page number 5
Hyperlink [Aspose.com](http://www.aspose.com)
TOC
[Font Formatting 1](#_toc76372684)
[Paragraph Formatting 1](#_toc76372685)
[Non-English Characters 2](#_toc76372686)
[Tables 2](#_toc76372687)
[Lists 2](#_toc76372688)
[Images 4](#_toc76372689)
[Fields 5](#_toc76372690)
# **Form Fields**
Edit <a name="text1"></a>test text
Checkbox <a name="check1"></a>
Combobox <a name="dropdown1"></a>
# **Footnotes and Endnotes**
This line has a footnote at the end.[^1]
This line has an endnote at the end.[^2]
[^1]: Footnote 1.
[^2]: Endnote 1.
Özet
GroupDocs.Markdown for .NET, geniş bir belge formatı yelpazesini LLM + RAG sistemleri için hazır, anlamsal Markdown’a dönüştürmenize yardımcı olur. Belge yapısını ve anlamını korur, yerinde çalışır ve yaygın kurumsal formatları destekler — büyük belge koleksiyonlarını AI tüketimi için hazırlaması gereken organizasyonlar için pratik bir seçimdir.
Daha fazla bilgi
- Ürün ana sayfası: https://products.groupdocs.com/markdown/net/
- Dokümantasyon: https://docs.groupdocs.com/markdown/net/
- Lisans bilgileri: https://about.groupdocs.com/legal/
- İndirmeler: https://releases.groupdocs.com/markdown/net/
Destek ve geri bildirim
Sorularınız veya teknik yardıma ihtiyacınız olduğunda lütfen Free Support Forum adresini kullanın — size yardımcı olmaktan memnuniyet duyarız.