
Udělejte své firemní dokumenty připravené pro AI — spolehlivě, lokálně a sémanticky.
Je poměrně běžné, že organizace uchovávají svou dokumentaci ve formátech PDF, DOCX, XLSX a ePub. Zatímco LLM (large language models) dobře pracují s HTML nebo prostým textem, tyto nativní formáty dokumentů vyžadují konverzi, než je lze efektivně použít v LLM + RAG pipelinech, kde chceme komunikovat s dokumentem nebo sadou dokumentů.
LLM (Large Language Model) — předtrénovaný AI model, který generuje text a odpovědi na základě velkých textových korpusů.
RAG (Retrieval-Augmented Generation) — přístup, který kombinuje LLM s externí znalostní bází (například firemními dokumenty), aby model mohl vyhledávat a uvažovat nad obsahem domény.
Následující sekvenční diagram ilustruje typické kroky při generování odpovědi na otázku:
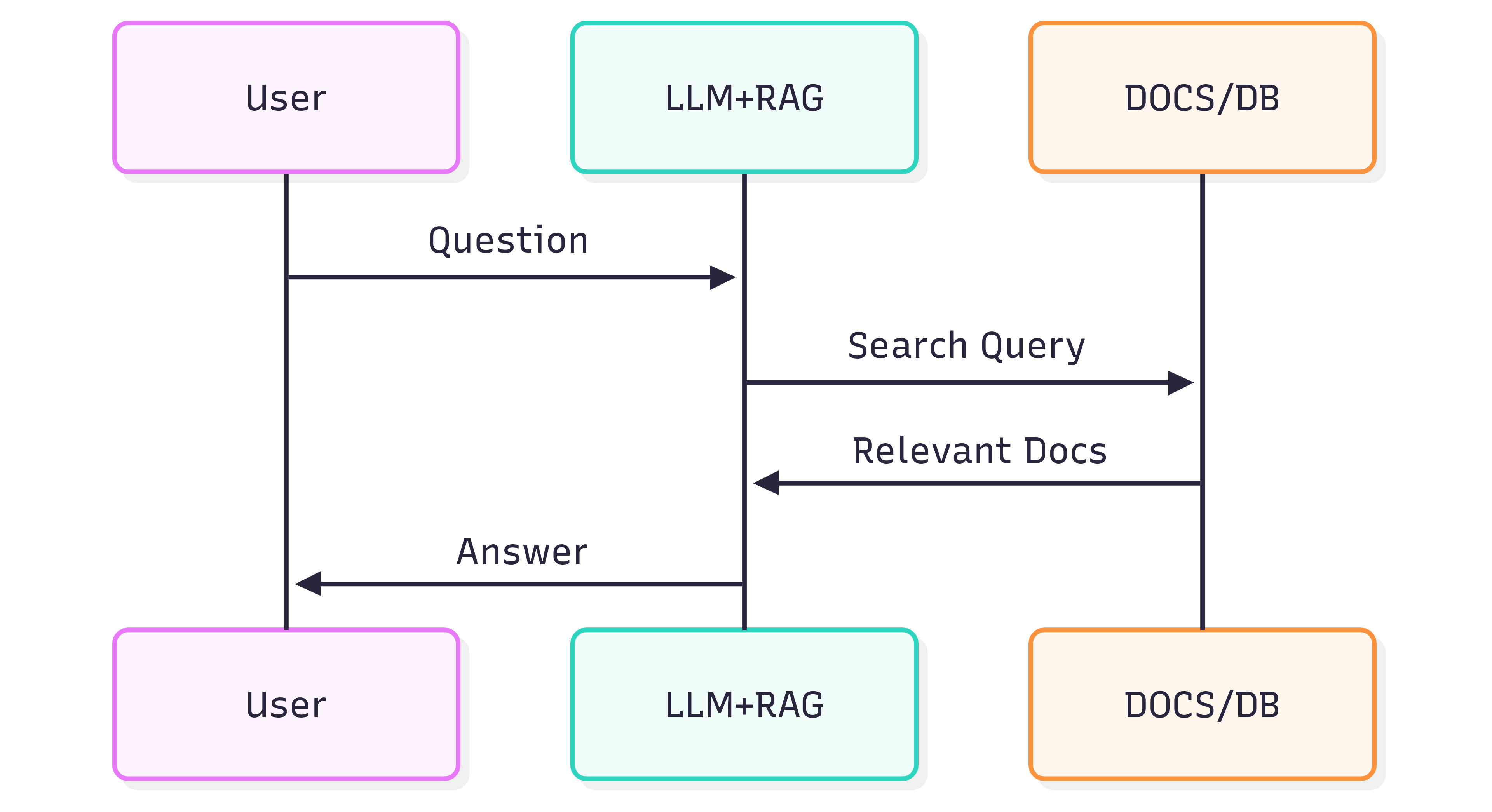
Kvalita odpovědí, které získáte od systému (LLM + RAG), závisí jak na samotném systému, tak na tom, jak dobře zdrojové dokumenty zachovají svou strukturu a význam při předání do retrieval pipeline.
Problém
Formátování dokumentu není jen vizuální — nese sémantiku. Nadpisy, seznamy, tabulky, tučné/kurzívní zvýraznění, popisky a vložené obrázky všechny předávají význam, který pomáhá LLM pochopit kontext. Naivní konverze dokumentů (například pomocí OCR, které zachází s každou stránkou jako s plochým obrázkem) často tuto sémantiku ztrácí. Výsledkem může být, že RAG retrieval a následné odpovědi LLM jsou nepřesné nebo šumivé.
OCR může pomoci u skenovaných dokumentů, ale často odstraňuje strukturu (seznamy rozdělené přes stránky, špatně interpretované okraje tabulek, ztracené anotace). Navíc přidává náklady a infrastrukturu při zpracování velkých archivů.
Řešení
Alternativní přístup spočívá v parsování dokumentů se strukturálním povědomím a exportu této struktury do sémantického, LLM‑přátelského formátu — Markdown. Markdown je lehký, široce podporovaný a zachovává nadpisy, seznamy, tabulky, bloky kódu, zvýraznění, popisky a odkazy na obrázky — přesně ty vlastnosti, které zlepšují kvalitu retrievalu.
GroupDocs.Markdown for .NET převádí populární formáty dokumentů (PDF, DOCX, XLSX, ePub a další) do čistého, sémantického Markdownu vhodného pro ingestaci do RAG systémů. Jedná se o on‑premise .NET knihovnu, takže veškeré zpracování probíhá uvnitř vašeho prostředí — žádné externí služby, žádné úniky dat a žádná závislost na vzdálených GPU.
Jak začít
GroupDocs.Markdown for .NET je dostupný jako NuGet balíček, a také jako MSI a ZIP ke stažení.
Nainstalujte NuGet balíček pomocí .NET CLI:
dotnet add package GroupDocs.Markdown
Nebo si stáhněte instalátory a sestavení z oficiální stránky ke stažení: https://releases.groupdocs.com/markdown/net/
Příklad použití (přidejte do Program.cs):
// Import the namespace
using GroupDocs.Markdown;
// Set the license (optional for evaluation)
License.Set("GroupDocs.Markdown.lic");
// Instantiate the converter for a source document
var converter = new MarkdownConverter("rich-text-formatting.docx");
// Convert and save output to file
converter.Convert("rich-text-formatting.md");
Převodní soubor rich-text-formatting.md bude uložen ve stejné složce jako vaše aplikace.
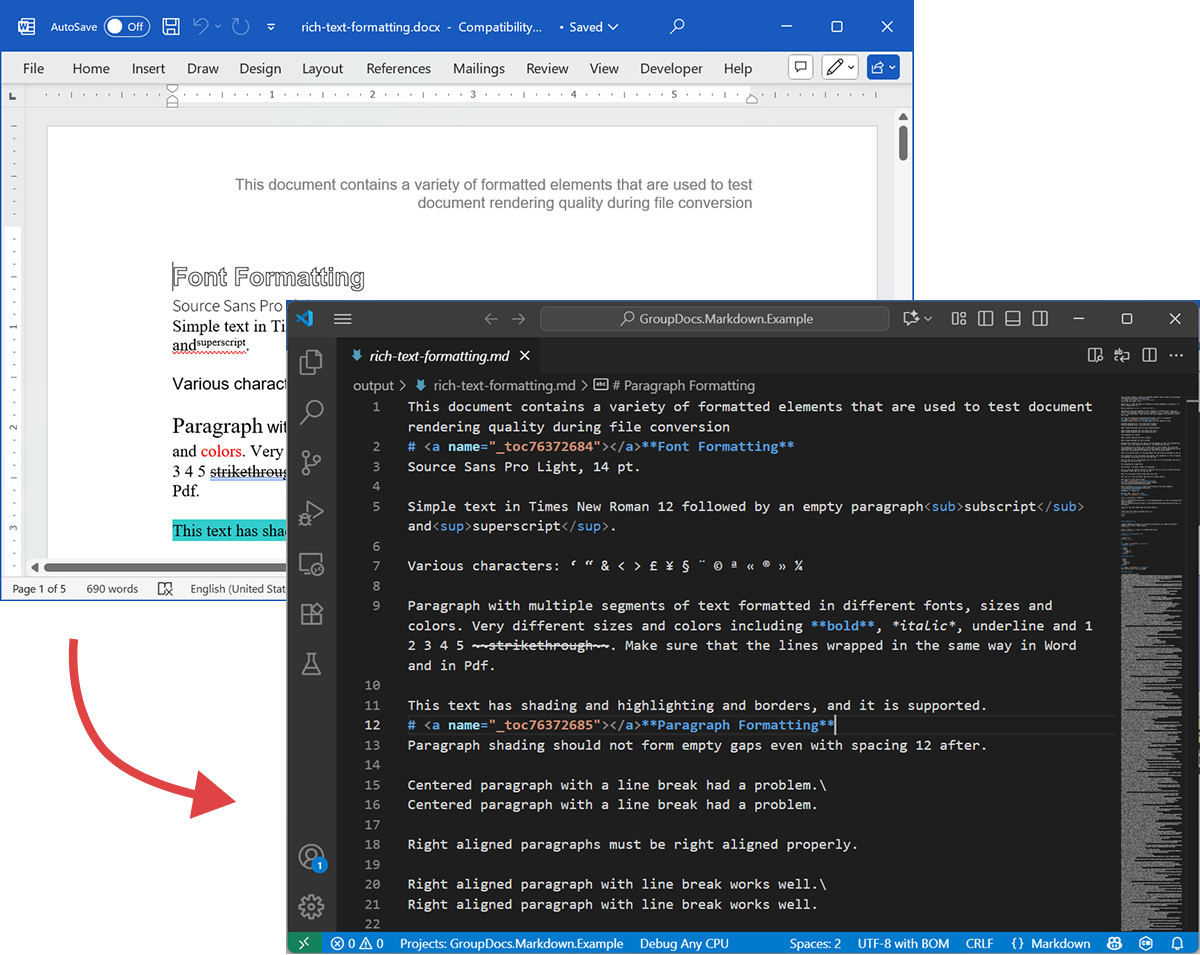
Následující snímek obrazovky ukazuje vstupní soubor DOCX a výstupní Markdown.
Pokud spustíte bez licence, režim hodnocení zpracuje omezený počet stránek (například první tři stránky). Chcete‑li vyzkoušet plnou verzi produktu, požádejte o dočasnou licenci.
Pro získání dočasné licence otevřete Purchase Wizard, uveďte kontaktní údaje a klikněte na Get a temporary license v kroku Contact Details. Dočasná licence vám bude zaslána e‑mailem.
Více informací o dočasných licencích: https://purchase.groupdocs.com/temporary-license/.
Podporované formáty souborů
GroupDocs.Markdown for .NET podporuje širokou škálu běžných firemních a e‑knihových formátů. Kompletní seznam podporovaných přípon:
- PDF
pdf
- Tabulky
.xls,.xlsx,.xlsb,.xlsm,.xlt,.xltx,.xltm,.xlam,.csv,.tsv,.ods,.ots,.fods,.numbers,.sxc
- Word / Rich Text
.doc,.docx,.dot,.dotm,.dotx,.docm,.rtf,.odt,.ott
- E‑knihy
.azw3,.mobi,.epub
- Text / Značkování / Nápověda
.chm,.xml,.txt
Jak to funguje (interní — vysoká úroveň)
Když je dokument zpracován, probíhají dvě hlavní fáze:
-
Document model extraction
Dokument je parsován do paměťového objektového modelu, který představuje strukturální prvky (odstavce, nadpisy, seznamy, tabulky, obrázky, poznámky pod čarou, anotace atd.). Parser se snaží zachovat sémantiku (například vnoření seznamů, buňky tabulek a popisky obrázků). -
Markdown generation
Objektový model je procházen a převáděn do Markdownu podle konfigurovatelných možností konverze (jak zacházet s obrázky, formátováním tabulek, úrovněmi nadpisů, speciálními anotacemi atd.). Výsledkem je čitelný, sémanticky významný Markdown soubor připravený k indexaci vaším RAG pipelinem.
Příklad exportu
Ukázkový kód výše ukazuje, jak exportovat DOCX do Markdownu. Vezměme tento kód a podívejme se na zdrojové a výstupní soubory jako demonstraci.
Source DOCX
Zdrojový soubor rich-text-formatting.docx obsahuje různé bloky obsahu a je silně formátován tak, aby zvýraznil hlavní sémantické elementy.
Output Markdown
Výstupní obsah rich-text-formatting.md je uveden níže a ukazuje, jak jsou různé formátovací prvky reprezentovány v generovaném Markdown souboru.
This document contains a variety of formatted elements that are used to test document rendering quality during file conversion
# <a name="_toc76372684"></a>**Font Formatting**
Source Sans Pro Light, 14 pt.
Simple text in Times New Roman 12 followed by an empty paragraph<sub>subscript</sub> and<sup>superscript</sup>.
Various characters: ‘ “ & < > £ ¥ § ¨ © ª « ® » ¼
Paragraph with multiple segments of text formatted in different fonts, sizes and colors. Very different sizes and colors including **bold**, *italic*, underline and 1 2 3 4 5 ~~strikethrough~~. Make sure that the lines wrapped in the same way in Word and in Pdf.
This text has shading and highlighting and borders, and it is supported.
# <a name="_toc76372685"></a>**Paragraph Formatting**
Paragraph shading should not form empty gaps even with spacing 12 after.
Centered paragraph with a line break had a problem.\
Centered paragraph with a line break had a problem.
Right aligned paragraphs must be right aligned properly.
Right aligned paragraph with line break works well.\
Right aligned paragraph with line break works well.
This paragraph has a border.
Right aligned condensed text had a problem.
Right aligned expanded text had a problem.
Spacing after and before do not add up, just the greater is used. This paragraph has 12 after. Also, when indents are different, the shading does not join.
This paragraph has 12 before, but in total there is only 12 above. Also note that shading belongs to the paragraph at the top and shading of this paragraph does not go down unless next paragraph has shading too. There are 24 points below.
There are 24 points above, but the gap between this and previous paragraph is only 24.
This paragraph is a test for double line spacing. This paragraph is a test for double line spacing. It also have 0.5” for the first line.
This is a test for 1.5 line spacing. This is a test for 1.5 line spacing. Also has -0.5” indent for the first line.
This paragraph has a page break
and centered. It actually creates two paragraphs.
This is a test for Exactly 20 points of spacing. This is a test for Exactly 20 points of spacing. TTTTTT (20, 22, 24, 26, 28, 30).
There is a continuous section break after this line.
This line is in the new section. Next here is an empty section.
This line is in the fourth section.
# <a name="_toc76372686"></a>**Paragraph Justify**
This is a justified paragraph with a single segment. 111111111111111111111111111111111111111111.
Also a justified **paragraph** reset to left because of multiple segments. 111111111111111111111111111111111111111111.
# **Non-English Characters**
Wingdings: (x, Symbol: WÄ
Russian: Теперь немного по русски.
# <a name="_toc76372687"></a>**Tables**
|Cell 1.1 Left|Cell 1.2 Right|||
| :- | -: | :- | :- |
|Cell 2.1 Centered vertically|Cell 2.2 with background|Cell 2.3 with line break<br>and coloured border.||
|Cell 3.1 Bottom vertically|<p>Cell 3.2</p><p>Centered</p><p>Horizontally</p>|Cell 3.3 No border||
|Left red, blue top, green right and yellow bottom.|
| :- |
|Table with left indent and merged cells.||||
| :- | :- | :- | :- |
|||||
|||||
**Cell padding etc.**
|<p>Cell padding.</p><p>Top: 0.1, bottom 0.2</p><p>Left: 0.5, Right 0.4</p>|Zero padding on all sides, right aligned.|
| :- | -: |
|Outer 1.1|Outer 1.2. There is a nested table here||
| :- | :-: | -: |
|**Nested 1.1**|**Nested 1.2**|
| :- | :- |
|||Outer 1.3|
| :- | :-: | -: |
#
# <a name="_toc76372688"></a>**Lists**
**Numbered list:**
1. Item 1
1. Item 2
1. Item 2.1
1. Item 2.2
1. Item 3
**Bulleted list:**
- Item 1
- Item 2
- Item 2.1
- Item 2.2
- Item 3
#
# <a name="_toc76372689"></a>**Images**
This section starts from a new page.
**Ellipse text**
There is an image in a black border in the top right corner, but it will drop down into the text. There is also a transparent ellipse with text that overlaps the picture.
Inline JPEG in a separate paragraph.

Inline GIF scaled 50% and WMF scaled 25% in a paragraph. This text is before the image and  this text is after the image.
Images in a table. Left and right aligned.
|||
| :- | -: |
Inline text box  is here and inline ellipse  is here.
New section that starts from a new page is here.
It has portrait orientation and margins.
# <a name="_toc76372690"></a>**Fields**
Merge field «FirstName»
Page number 5
Hyperlink [Aspose.com](http://www.aspose.com)
TOC
[Font Formatting 1](#_toc76372684)
[Paragraph Formatting 1](#_toc76372685)
[Non-English Characters 2](#_toc76372686)
[Tables 2](#_toc76372687)
[Lists 2](#_toc76372688)
[Images 4](#_toc76372689)
[Fields 5](#_toc76372690)
# **Form Fields**
Edit <a name="text1"></a>test text
Checkbox <a name="check1"></a>
Combobox <a name="dropdown1"></a>
# **Footnotes and Endnotes**
This line has a footnote at the end.[^1]
This line has an endnote at the end.[^2]
[^1]: Footnote 1.
[^2]: Endnote 1.
Shrnutí
GroupDocs.Markdown for .NET vám pomůže převést širokou škálu formátů dokumentů do sémantického Markdownu připraveného pro LLM + RAG systémy. Zachovává strukturu a význam dokumentu, běží on‑premise a podporuje běžné firemní formáty — což z něj činí praktickou volbu pro organizace, které potřebují připravit velké sbírky dokumentů pro konzumaci AI.
Další informace
- Domovská stránka produktu: https://products.groupdocs.com/markdown/net/
- Dokumentace: https://docs.groupdocs.com/markdown/net/
- Informace o licenci: https://about.groupdocs.com/legal/
- Stažení: https://releases.groupdocs.com/markdown/net/
Podpora a zpětná vazba
Pro otázky nebo technickou pomoc použijte naše Free Support Forum — rádi vám pomůžeme.