
اسناد سازمانی خود را برای هوش مصنوعی آماده کنید — بهصورت قابلاعتماد، درونسازمانی و معنایی.
امری رایج است که سازمانها اسناد خود را در قالبهای PDF، DOCX، XLSX و ePub نگهداری میکنند. در حالی که LLMها (large language models) با HTML یا متن ساده خوب کار میکنند، این قالبهای بومی سند نیاز به تبدیل دارند تا بتوانند بهصورت مؤثر در خطوط لوله LLM + RAG که میخواهیم با یک سند یا مجموعهای از اسناد گفتگو کنیم، استفاده شوند.
LLM (Large Language Model) — یک مدل هوش مصنوعی پیشآموزشدیده که بر پایهٔ مجموعههای بزرگ متنی متن تولید و پاسخ میدهد.
RAG (Retrieval‑Augmented Generation) — رویکردی که LLM را با یک پایگاه دانش خارجی (مثلاً اسناد سازمانی) ترکیب میکند تا مدل بتواند محتویات دامنه را بازیابی و بر آن استدلال کند.
نمودار توالی زیر گامهای معمول در تولید پاسخ به یک سؤال را نشان میدهد:
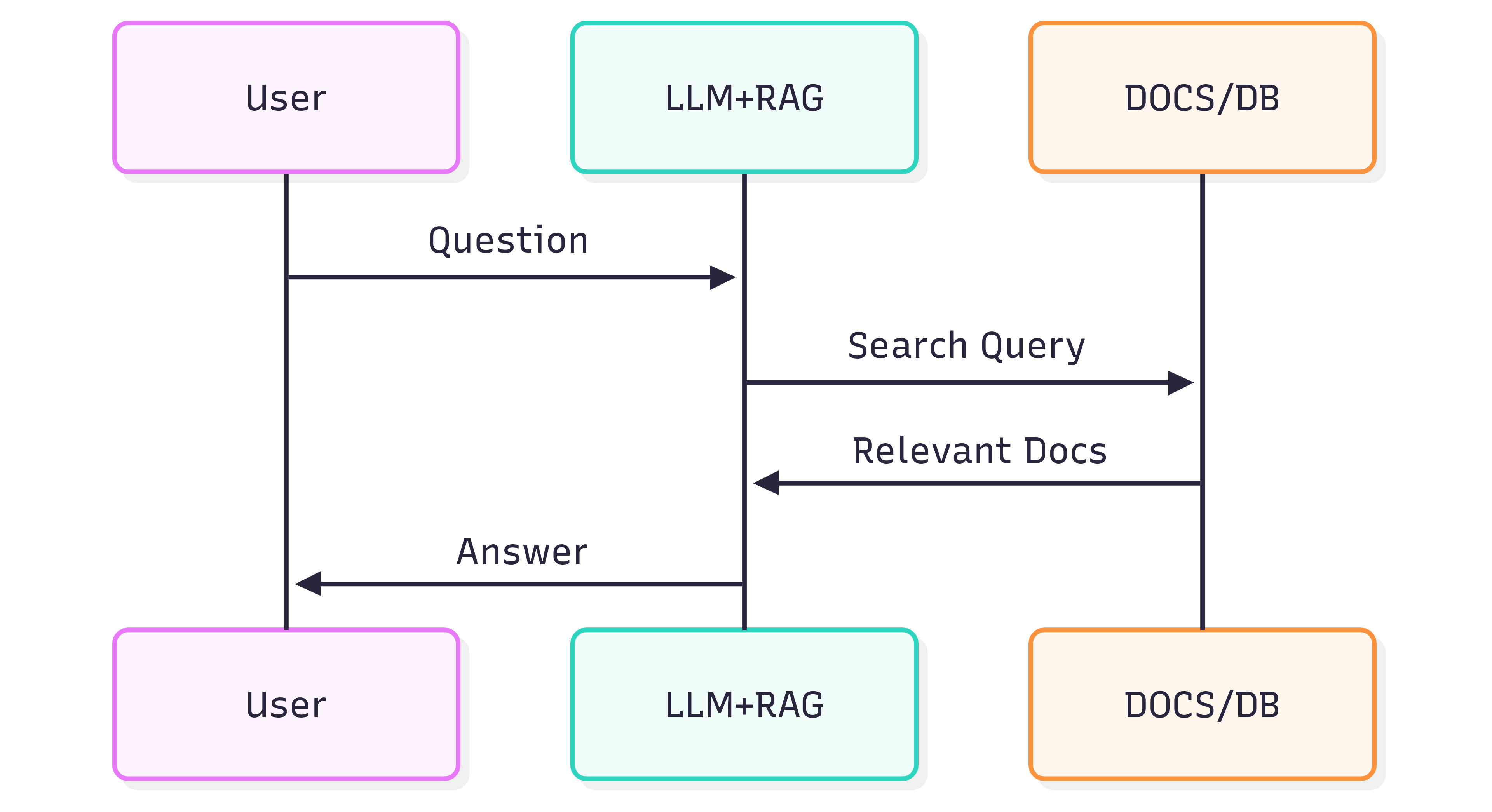
کیفیت پاسخهایی که از یک سیستم (LLM + RAG) دریافت میکنید، هم به خود سیستم و هم به اینکه اسناد منبع چقدر ساختار و معنای خود را هنگام ورود به خط لوله بازیابی حفظ میکنند، بستگی دارد.
مشکل
قالببندی سند فقط بصری نیست — معنایی نیز دارد. عناوین، فهرستها، جدولها، تأکیدهای بولد/ایتالیک، زیرنویسها و تصاویر درونمتنی همگی معنایی را منتقل میکنند که به LLM کمک میکند زمینه را درک کند. تبدیل سادهٔ اسناد (مثلاً با OCR که هر صفحه را بهعنوان یک تصویر صاف در نظر میگیرد) اغلب این معانی را از دست میدهد. در نتیجه، بازیابی RAG و پاسخهای LLM میتوانند نادرست یا پر سر و صدا شوند.
OCR میتواند برای اسناد اسکنشده مفید باشد اما اغلب ساختار را حذف میکند (فهرستهای تقسیمشده بین صفحات، مرزهای جدول که بهدرستی تفسیر نمیشوند، حاشیهنویسیهای از دست رفته). همچنین هزینه و بار زیرساختی را هنگام پردازش آرشیوهای بزرگ اضافه میکند.
راهحل
یک رویکرد جایگزین این است که اسناد را با آگاهی ساختاری تجزیه‑تحلیل کنیم و آن ساختار را به قالبی معنایی و سازگار با LLM — Markdown — صادر کنیم. Markdown سبک، بهطور گسترده پشتیبانی میشود و عناوین، فهرستها، جدولها، بلوکهای کد، تأکیدها، زیرنویسها و ارجاعهای تصویر را حفظ میکند — دقیقاً ویژگیهایی که کیفیت بازیابی را بهبود میبخشند.
GroupDocs.Markdown for .NET قالبهای محبوب سند (PDF، DOCX، XLSX، ePub و موارد دیگر) را به Markdown تمیز و معنایی تبدیل میکند که برای ورود به سیستمهای RAG مناسب است. این یک کتابخانهٔ .NET درونسازمانی است، بنابراین تمام پردازشها داخل محیط شما انجام میشود — بدون سرویسهای خارجی، بدون نشت داده و بدون وابستگی به GPUهای راهدور.
چگونگی شروع
GroupDocs.Markdown for .NET بهصورت بستهٔ NuGet در دسترس است و همچنین بهصورت MSI و ZIP قابل دانلود میباشد.
بستهٔ NuGet را با خط فرمان .NET نصب کنید:
dotnet add package GroupDocs.Markdown
یا نصبکنندهها و اسمبلیها را از صفحهٔ دانلودهای رسمی دریافت کنید: https://releases.groupdocs.com/markdown/net/
نمونهٔ استفاده (به Program.cs اضافه کنید):
// Import the namespace
using GroupDocs.Markdown;
// Set the license (optional for evaluation)
License.Set("GroupDocs.Markdown.lic");
// Instantiate the converter for a source document
var converter = new MarkdownConverter("rich-text-formatting.docx");
// Convert and save output to file
converter.Convert("rich-text-formatting.md");
فایل rich-text-formatting.md تبدیلشده در همان پوشهای که برنامهٔ شما قرار دارد ذخیره میشود.
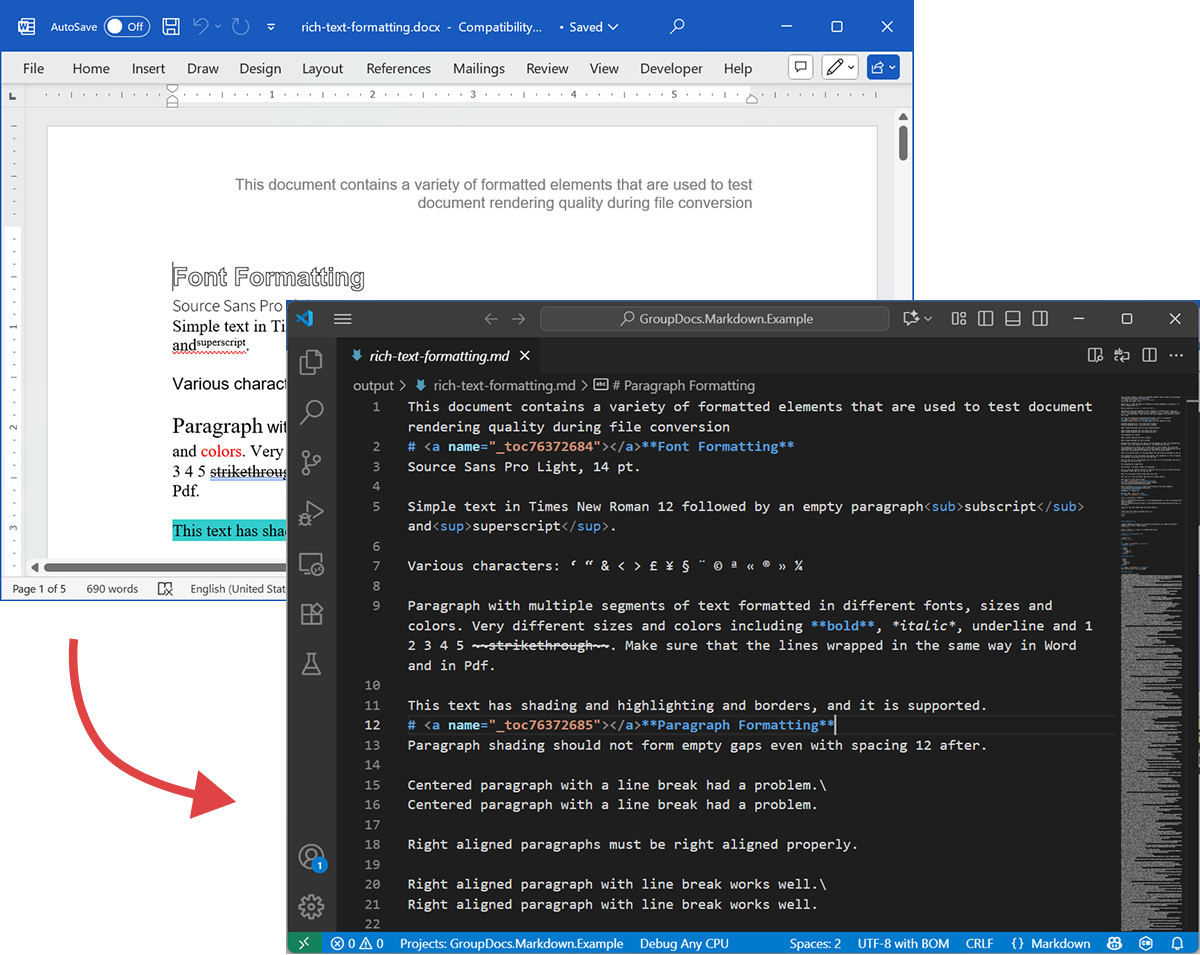
اسکرینشات زیر فایل DOCX ورودی و خروجی Markdown را نشان میدهد.
اگر بدون لایسنس اجرا کنید، حالت ارزیابی تعداد محدودی صفحه (مثلاً سه صفحهٔ اول) را پردازش میکند. برای امتحان محصول کامل، یک لایسنس موقت درخواست کنید.
برای درخواست لایسنس موقت، به Purchase Wizard بروید، جزئیات تماس را وارد کنید و در مرحلهٔ Contact Details روی Get a temporary license کلیک کنید. لایسنس موقت برای شما ایمیل خواهد شد.
اطلاعات بیشتر درباره لایسنسهای موقت: https://purchase.groupdocs.com/temporary-license/.
فرمتهای فایل پشتیبانیشده
GroupDocs.Markdown for .NET مجموعهٔ گستردهای از فرمتهای رایج سازمانی و کتابهای الکترونیکی را پشتیبانی میکند. فهرست کامل پسوندهای پشتیبانیشده:
- PDF
pdf
- Spreadsheets
.xls,.xlsx,.xlsb,.xlsm,.xlt,.xltx,.xltm,.xlam,.csv,.tsv,.ods,.ots,.fods,.numbers,.sxc
- Word / Rich Text
.doc,.docx,.dot,.dotm,.dotx,.docm,.rtf,.odt,.ott
- Ebooks
.azw3,.mobi,.epub
- Text / Markup / Help
.chm,.xml,.txt
نحوه کار (درونیسازی — سطح بالا)
هنگامی که یک سند پردازش میشود، دو فاز اصلی رخ میدهد:
-
استخراج مدل سند
سند به یک مدل شیء در حافظه تجزیه میشود که عناصر ساختاری (پاراگرافها، عناوین، فهرستها، جدولها، تصاویر، پانوشتها، حاشیهنویسیها و غیره) را نمایندگی میکند. تجزیهکننده سعی میکند معانی را حفظ کند (مثلاً تو در تویی فهرستها، سلولهای جدول و زیرنویسهای تصویر). -
تولید Markdown
مدل شیء پیمایش شده و بر اساس گزینههای قابلپیکربندی تبدیل (نحوهٔ پردازش تصاویر، قالببندی جدول، سطوح عناوین، حاشیهنویسیهای خاص و غیره) به Markdown تبدیل میشود. نتیجه یک فایل Markdown خوانا و معنایی است که برای ایندکسگذاری توسط خط لولهٔ RAG شما آماده است.
مثال خروجی
کد نمونهٔ بالا نشان میدهد چگونه DOCX به Markdown صادر میشود. حال این مثال کد را میگیریم و به فایلهای منبع و خروجی نگاهی میاندازیم.
DOCX منبع
فایل منبع rich-text-formatting.docx شامل بلوکهای محتوا مختلف است و بهطور گستردهای قالببندی شده تا عناصر معنایی اصلی را برجسته کند.
Markdown خروجی
محتوای خروجی rich-text-formatting.md در زیر آورده شده است و نشان میدهد چگونه عناصر قالببندی مختلف در فایل Markdown تولیدشده نمایان میشوند.
This document contains a variety of formatted elements that are used to test document rendering quality during file conversion
# <a name="_toc76372684"></a>**Font Formatting**
Source Sans Pro Light, 14 pt.
Simple text in Times New Roman 12 followed by an empty paragraph<sub>subscript</sub> and<sup>superscript</sup>.
Various characters: ‘ “ & < > £ ¥ § ¨ © ª « ® » ¼
Paragraph with multiple segments of text formatted in different fonts, sizes and colors. Very different sizes and colors including **bold**, *italic*, underline and 1 2 3 4 5 ~~strikethrough~~. Make sure that the lines wrapped in the same way in Word and in Pdf.
This text has shading and highlighting and borders, and it is supported.
# <a name="_toc76372685"></a>**Paragraph Formatting**
Paragraph shading should not form empty gaps even with spacing 12 after.
Centered paragraph with a line break had a problem.\
Centered paragraph with a line break had a problem.
Right aligned paragraphs must be right aligned properly.
Right aligned paragraph with line break works well.\
Right aligned paragraph with line break works well.
This paragraph has a border.
Right aligned condensed text had a problem.
Right aligned expanded text had a problem.
Spacing after and before do not add up, just the greater is used. This paragraph has 12 after. Also, when indents are different, the shading does not join.
This paragraph has 12 before, but in total there is only 12 above. Also note that shading belongs to the paragraph at the top and shading of this paragraph does not go down unless next paragraph has shading too. There are 24 points below.
There are 24 points above, but the gap between this and previous paragraph is only 24.
This paragraph is a test for double line spacing. This paragraph is a test for double line spacing. It also have 0.5” for the first line.
This is a test for 1.5 line spacing. This is a test for 1.5 line spacing. Also has -0.5” indent for the first line.
This paragraph has a page break
and centered. It actually creates two paragraphs.
This is a test for Exactly 20 points of spacing. This is a test for Exactly 20 points of spacing. TTTTTT (20, 22, 24, 26, 28, 30).
There is a continuous section break after this line.
This line is in the new section. Next here is an empty section.
This line is in the fourth section.
# <a name="_toc76372686"></a>**Paragraph Justify**
This is a justified paragraph with a single segment. 111111111111111111111111111111111111111111.
Also a justified **paragraph** reset to left because of multiple segments. 111111111111111111111111111111111111111111.
# **Non-English Characters**
Wingdings: (x, Symbol: WÄ
Russian: Теперь немного по русски.
# <a name="_toc76372687"></a>**Tables**
|Cell 1.1 Left|Cell 1.2 Right|||
| :- | -: | :- | :- |
|Cell 2.1 Centered vertically|Cell 2.2 with background|Cell 2.3 with line break<br>and coloured border.||
|Cell 3.1 Bottom vertically|<p>Cell 3.2</p><p>Centered</p><p>Horizontally</p>|Cell 3.3 No border||
|Left red, blue top, green right and yellow bottom.|
| :- |
|Table with left indent and merged cells.||||
| :- | :- | :- | :- |
|||||
|||||
**Cell padding etc.**
|<p>Cell padding.</p><p>Top: 0.1, bottom 0.2</p><p>Left: 0.5, Right 0.4</p>|Zero padding on all sides, right aligned.|
| :- | -: |
|Outer 1.1|Outer 1.2. There is a nested table here||
| :- | :-: | -: |
|**Nested 1.1**|**Nested 1.2**|
| :- | :- |
|||Outer 1.3|
| :- | :-: | -: |
#
# <a name="_toc76372688"></a>**Lists**
**Numbered list:**
1. Item 1
1. Item 2
1. Item 2.1
1. Item 2.2
1. Item 3
**Bulleted list:**
- Item 1
- Item 2
- Item 2.1
- Item 2.2
- Item 3
#
# <a name="_toc76372689"></a>**Images**
This section starts from a new page.
**Ellipse text**
There is an image in a black border in the top right corner, but it will drop down into the text. There is also a transparent ellipse with text that overlaps the picture.
Inline JPEG in a separate paragraph.

Inline GIF scaled 50% and WMF scaled 25% in a paragraph. This text is before the image and  this text is after the image.
Images in a table. Left and right aligned.
|||
| :- | -: |
Inline text box  is here and inline ellipse  is here.
New section that starts from a new page is here.
It has portrait orientation and margins.
# <a name="_toc76372690"></a>**Fields**
Merge field «FirstName»
Page number 5
Hyperlink [Aspose.com](http://www.aspose.com)
TOC
[Font Formatting 1](#_toc76372684)
[Paragraph Formatting 1](#_toc76372685)
[Non-English Characters 2](#_toc76372686)
[Tables 2](#_toc76372687)
[Lists 2](#_toc76372688)
[Images 4](#_toc76372689)
[Fields 5](#_toc76372690)
# **Form Fields**
Edit <a name="text1"></a>test text
Checkbox <a name="check1"></a>
Combobox <a name="dropdown1"></a>
# **Footnotes and Endnotes**
This line has a footnote at the end.[^1]
This line has an endnote at the end.[^2]
[^1]: Footnote 1.
[^2]: Endnote 1.
خلاصه
GroupDocs.Markdown for .NET به شما کمک میکند تا طیف وسیعی از فرمتهای سند را به Markdown معنایی تبدیل کنید که برای سیستمهای LLM + RAG آماده است. این ابزار ساختار و معنای سند را حفظ میکند، بهصورت درونسازمانی اجرا میشود و فرمتهای رایج سازمانی را پشتیبانی میکند — بنابراین انتخابی عملی برای سازمانهایی است که نیاز به آمادهسازی مجموعههای بزرگ سند برای مصرف هوش مصنوعی دارند.
بیشتر بیاموزید
- صفحهٔ محصول: https://products.groupdocs.com/markdown/net/
- مستندات: https://docs.groupdocs.com/markdown/net/
- اطلاعات لایسنس: https://about.groupdocs.com/legal/
- دانلودها: https://releases.groupdocs.com/markdown/net/
پشتیبانی و بازخورد
برای سؤالات یا کمک فنی، لطفاً از Free Support Forum استفاده کنید — خوشحال میشویم که کمک کنیم.