
Uczyń swoje dokumenty firmowe gotowymi na AI — niezawodnie, lokalnie i semantycznie.
Dość powszechnym przypadkiem jest, gdy organizacje przechowują swoją dokumentację w formatach PDF, DOCX, XLSX i ePub. Podczas gdy LLM (large language models) dobrze radzą sobie z HTML lub zwykłym tekstem, te natywne formaty dokumentów wymagają konwersji, zanim będą mogły być skutecznie wykorzystywane w potokach LLM + RAG, w których chcemy rozmawiać z dokumentem lub zestawem dokumentów.
LLM (Large Language Model) — wstępnie wytrenowany model AI, który generuje tekst i odpowiedzi na podstawie dużych korpusów tekstowych.
RAG (Retrieval‑Augmented Generation) — podejście łączące LLM z zewnętrzną bazą wiedzy (na przykład dokumentami firmowymi), dzięki czemu model może pobierać i rozumować nad treścią domenową.
Poniższy diagram sekwencji ilustruje typowe kroki związane z generowaniem odpowiedzi na pytanie:
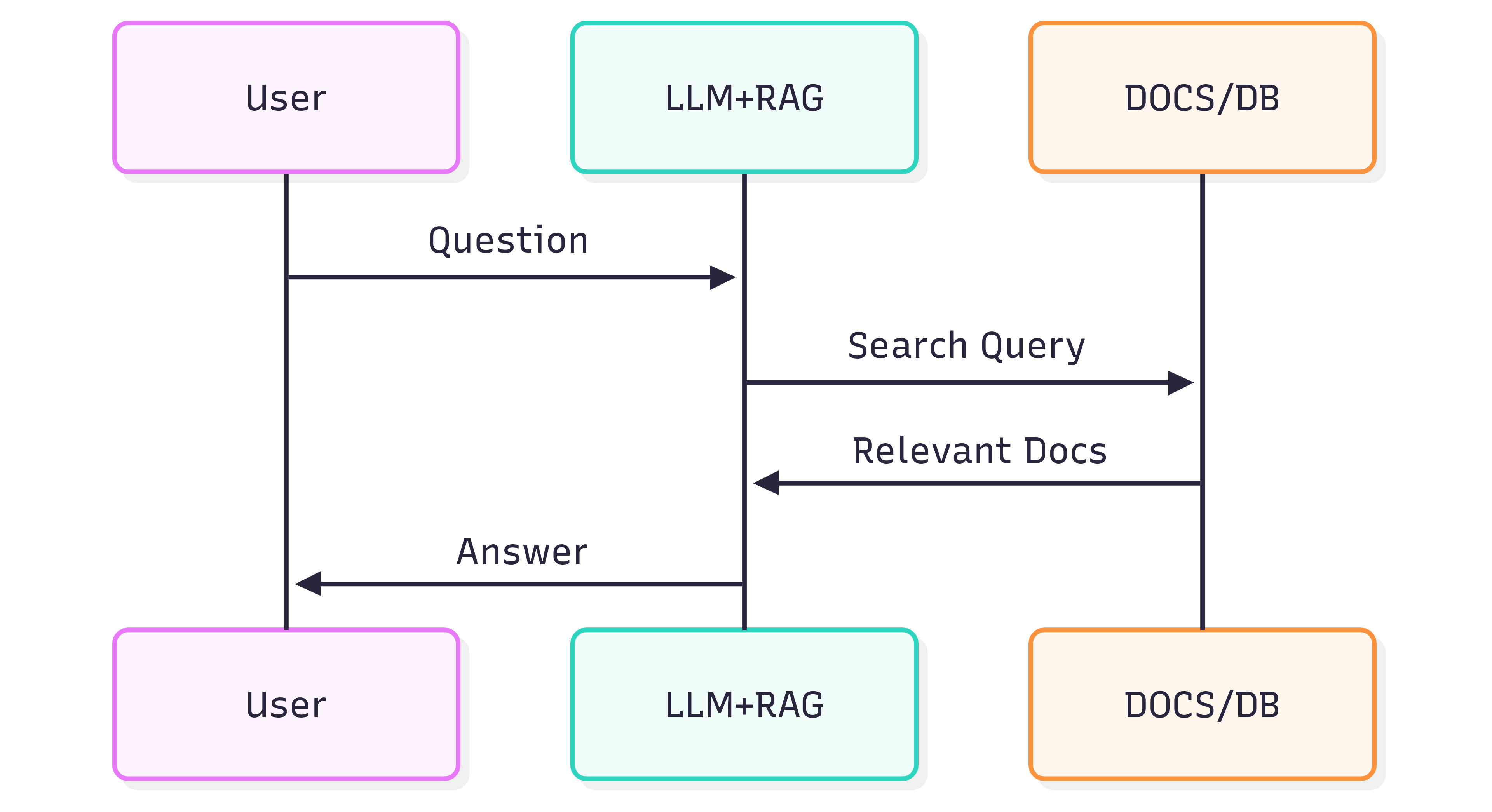
Jakość odpowiedzi uzyskiwanych z Systemu (LLM + RAG) zależy zarówno od samego Systemu, jak i od tego, jak dobrze dokumenty źródłowe zachowują swoją strukturę i znaczenie po wprowadzeniu ich do potoku wyszukiwania.
Problem
Formatowanie dokumentu nie jest jedynie wizualne — niesie ze sobą semantykę. Nagłówki, listy, tabele, pogrubienie/pochylenie, podpisy i obrazy w tekście przekazują znaczenie, które pomaga LLM zrozumieć kontekst. Naiwna konwersja dokumentów (na przykład przy użyciu OCR, który traktuje każdą stronę jako płaski obraz) często traci tę semantykę. W rezultacie wyszukiwanie RAG i późniejsze odpowiedzi LLM mogą stać się nieprecyzyjne lub szumne.
OCR może pomóc w przypadku zeskanowanych dokumentów, ale często usuwa strukturę (listy podzielone na strony, nieprawidłowo interpretowane granice tabel, utracone adnotacje). Dodatkowo zwiększa koszty i wymaga infrastruktury przy przetwarzaniu dużych archiwów.
Rozwiązanie
Alternatywnym podejściem jest parsowanie dokumentów ze świadomością struktury i eksportowanie tej struktury do semantycznego, przyjaznego LLM formatu — Markdown. Markdown jest lekki, szeroko wspierany i zachowuje nagłówki, listy, tabele, bloki kodu, wyróżnienia, podpisy oraz odwołania do obrazów — dokładnie te cechy, które poprawiają jakość wyszukiwania.
GroupDocs.Markdown for .NET konwertuje popularne formaty dokumentów (PDF, DOCX, XLSX, ePub i inne) do czystego, semantycznego Markdownu, gotowego do załadowania do systemów RAG. To biblioteka .NET działająca lokalnie, więc całe przetwarzanie odbywa się w Twoim środowisku — bez usług zewnętrznych, wycieków danych i zależności od zdalnych GPU.
Jak rozpocząć
GroupDocs.Markdown for .NET jest dostępny jako pakiet NuGet, a także jako pliki MSI i ZIP.
Zainstaluj pakiet NuGet przy użyciu .NET CLI:
dotnet add package GroupDocs.Markdown
Lub pobierz instalatory i zestawy z oficjalnej strony pobierania: https://releases.groupdocs.com/markdown/net/
Przykładowe użycie (dodaj do Program.cs):
// Import the namespace
using GroupDocs.Markdown;
// Set the license (optional for evaluation)
License.Set("GroupDocs.Markdown.lic");
// Instantiate the converter for a source document
var converter = new MarkdownConverter("rich-text-formatting.docx");
// Convert and save output to file
converter.Convert("rich-text-formatting.md");
Przekonwertowany plik rich-text-formatting.md zostanie zapisany w tym samym folderze co Twoja aplikacja.
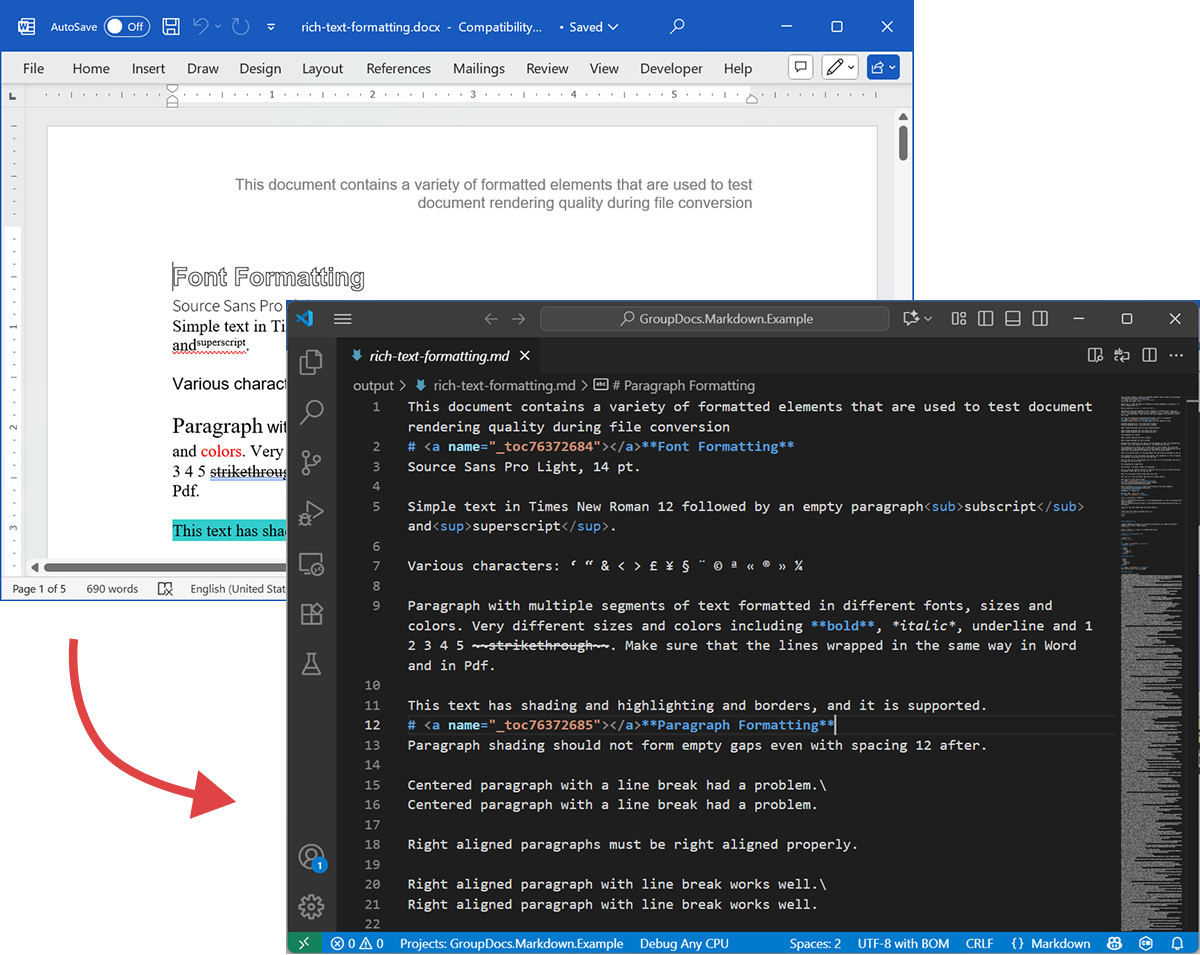
Poniższy zrzut ekranu pokazuje plik wejściowy DOCX oraz wynikowy Markdown.
Jeśli uruchomisz program bez licencji, tryb ewaluacyjny przetworzy ograniczoną liczbę stron (na przykład pierwsze trzy strony). Aby wypróbować pełną wersję produktu, zamów tymczasową licencję.
Aby zamówić tymczasową licencję, otwórz Purchase Wizard, podaj dane kontaktowe i kliknij Get a temporary license na etapie Contact Details. Tymczasowa licencja zostanie wysłana na Twój adres e‑mail.
Więcej informacji o tymczasowych licencjach: https://purchase.groupdocs.com/temporary-license/.
Obsługiwane formaty plików
GroupDocs.Markdown for .NET obsługuje szeroki zestaw powszechnych formatów korporacyjnych i ebooków. Pełna lista obsługiwanych rozszerzeń:
- PDF
pdf
- Arkusze kalkulacyjne
.xls,.xlsx,.xlsb,.xlsm,.xlt,.xltx,.xltm,.xlam,.csv,.tsv,.ods,.ots,.fods,.numbers,.sxc
- Word / Rich Text
.doc,.docx,.dot,.dotm,.dotx,.docm,.rtf,.odt,.ott
- Ebooki
.azw3,.mobi,.epub
- Tekst / Markup / Pomoc
.chm,.xml,.txt
Jak to działa (interny — wysoki poziom)
Podczas przetwarzania dokumentu zachodzą dwie główne fazy:
-
Ekstrakcja modelu dokumentu
Dokument jest parsowany do modelu obiektowego w pamięci, który reprezentuje elementy strukturalne (akapity, nagłówki, listy, tabele, obrazy, przypisy, adnotacje itp.). Parser dąży do zachowania semantyki (np. zagnieżdżenie list, komórki tabel i podpisy obrazów). -
Generowanie Markdown
Model obiektowy jest przeglądany i konwertowany do Markdown zgodnie z konfigurowalnymi opcjami konwersji (sposób obsługi obrazów, formatowanie tabel, poziomy nagłówków, specjalne adnotacje itp.). Wynikiem jest czytelny, semantycznie znaczący plik Markdown gotowy do indeksacji przez Twój potok RAG.
Przykład eksportu
Powyższy przykład kodu pokazuje, jak wyeksportować DOCX do Markdown. Weźmy ten przykład i przyjrzyjmy się plikom źródłowemu i wynikowemu jako demonstracji.
Źródłowy DOCX
Plik źródłowy rich-text-formatting.docx zawiera różnorodne bloki treści i jest mocno sformatowany, aby podkreślić główne elementy semantyczne.
Wynikowy Markdown
Zawartość wynikowa rich-text-formatting.md jest podana poniżej, pokazując, jak różne elementy formatowania są reprezentowane w wygenerowanym pliku Markdown.
This document contains a variety of formatted elements that are used to test document rendering quality during file conversion
# <a name="_toc76372684"></a>**Font Formatting**
Source Sans Pro Light, 14 pt.
Simple text in Times New Roman 12 followed by an empty paragraph<sub>subscript</sub> and<sup>superscript</sup>.
Various characters: ‘ “ & < > £ ¥ § ¨ © ª « ® » ¼
Paragraph with multiple segments of text formatted in different fonts, sizes and colors. Very different sizes and colors including **bold**, *italic*, underline and 1 2 3 4 5 ~~strikethrough~~. Make sure that the lines wrapped in the same way in Word and in Pdf.
This text has shading and highlighting and borders, and it is supported.
# <a name="_toc76372685"></a>**Paragraph Formatting**
Paragraph shading should not form empty gaps even with spacing 12 after.
Centered paragraph with a line break had a problem.\
Centered paragraph with a line break had a problem.
Right aligned paragraphs must be right aligned properly.
Right aligned paragraph with line break works well.\
Right aligned paragraph with line break works well.
This paragraph has a border.
Right aligned condensed text had a problem.
Right aligned expanded text had a problem.
Spacing after and before do not add up, just the greater is used. This paragraph has 12 after. Also, when indents are different, the shading does not join.
This paragraph has 12 before, but in total there is only 12 above. Also note that shading belongs to the paragraph at the top and shading of this paragraph does not go down unless next paragraph has shading too. There are 24 points below.
There are 24 points above, but the gap between this and previous paragraph is only 24.
This paragraph is a test for double line spacing. This paragraph is a test for double line spacing. It also have 0.5” for the first line.
This is a test for 1.5 line spacing. This is a test for 1.5 line spacing. Also has -0.5” indent for the first line.
This paragraph has a page break
and centered. It actually creates two paragraphs.
This is a test for Exactly 20 points of spacing. This is a test for Exactly 20 points of spacing. TTTTTT (20, 22, 24, 26, 28, 30).
There is a continuous section break after this line.
This line is in the new section. Next here is an empty section.
This line is in the fourth section.
# <a name="_toc76372686"></a>**Paragraph Justify**
This is a justified paragraph with a single segment. 111111111111111111111111111111111111111111.
Also a justified **paragraph** reset to left because of multiple segments. 111111111111111111111111111111111111111111.
# **Non-English Characters**
Wingdings: (x, Symbol: WÄ
Russian: Теперь немного по русски.
# <a name="_toc76372687"></a>**Tables**
|Cell 1.1 Left|Cell 1.2 Right|||
| :- | -: | :- | :- |
|Cell 2.1 Centered vertically|Cell 2.2 with background|Cell 2.3 with line break<br>and coloured border.||
|Cell 3.1 Bottom vertically|<p>Cell 3.2</p><p>Centered</p><p>Horizontally</p>|Cell 3.3 No border||
|Left red, blue top, green right and yellow bottom.|
| :- |
|Table with left indent and merged cells.||||
| :- | :- | :- | :- |
|||||
|||||
**Cell padding etc.**
|<p>Cell padding.</p><p>Top: 0.1, bottom 0.2</p><p>Left: 0.5, Right 0.4</p>|Zero padding on all sides, right aligned.|
| :- | -: |
|Outer 1.1|Outer 1.2. There is a nested table here||
| :- | :-: | -: |
|**Nested 1.1**|**Nested 1.2**|
| :- | :- |
|||Outer 1.3|
| :- | :-: | -: |
#
# <a name="_toc76372688"></a>**Lists**
**Numbered list:**
1. Item 1
1. Item 2
1. Item 2.1
1. Item 2.2
1. Item 3
**Bulleted list:**
- Item 1
- Item 2
- Item 2.1
- Item 2.2
- Item 3
#
# <a name="_toc76372689"></a>**Images**
This section starts from a new page.
**Ellipse text**
There is an image in a black border in the top right corner, but it will drop down into the text. There is also a transparent ellipse with text that overlaps the picture.
Inline JPEG in a separate paragraph.

Inline GIF scaled 50% and WMF scaled 25% in a paragraph. This text is before the image and  this text is after the image.
Images in a table. Left and right aligned.
|||
| :- | -: |
Inline text box  is here and inline ellipse  is here.
New section that starts from a new page is here.
It has portrait orientation and margins.
# <a name="_toc76372690"></a>**Fields**
Merge field «FirstName»
Page number 5
Hyperlink [Aspose.com](http://www.aspose.com)
TOC
[Font Formatting 1](#_toc76372684)
[Paragraph Formatting 1](#_toc76372685)
[Non-English Characters 2](#_toc76372686)
[Tables 2](#_toc76372687)
[Lists 2](#_toc76372688)
[Images 4](#_toc76372689)
[Fields 5](#_toc76372690)
# **Form Fields**
Edit <a name="text1"></a>test text
Checkbox <a name="check1"></a>
Combobox <a name="dropdown1"></a>
# **Footnotes and Endnotes**
This line has a footnote at the end.[^1]
This line has an endnote at the end.[^2]
[^1]: Footnote 1.
[^2]: Endnote 1.
Podsumowanie
GroupDocs.Markdown for .NET pomaga konwertować szeroką gamę formatów dokumentów do semantycznego Markdownu gotowego dla systemów LLM + RAG. Zachowuje strukturę i znaczenie dokumentu, działa lokalnie i obsługuje typowe formaty korporacyjne — co czyni go praktycznym wyborem dla organizacji, które muszą przygotować duże kolekcje dokumentów do konsumpcji przez AI.
Dowiedz się więcej
- Strona produktu: https://products.groupdocs.com/markdown/net/
- Dokumentacja: https://docs.groupdocs.com/markdown/net/
- Informacje o licencji: https://about.groupdocs.com/legal/
- Pobrania: https://releases.groupdocs.com/markdown/net/
Wsparcie i opinie
W razie pytań lub potrzeby pomocy technicznej, skorzystaj z naszego Free Support Forum — z przyjemnością pomożemy.